فهرست مطالب (کلیک تا مرور گر به آن نقطه از صفحه برود):
1- ضریب همبستگی (تحقيق همبستگي دو متغيري)
۱-الف- ضریب همبستگی پیرسون با مثال
۱-ب- تحلیل ضریب همبستگی پیرسون و آزمون فرضیه
۲-الف- روشهای ورود متغیرهای مستقل در مدل رگرسیون
۳- تحلیل ماتریس کواریانس یا همبستگی
سایت های تخصصی مدل سازی معادلات ساختاری
انواع همبستگی بین متغیرها
يكي از انواع روش هاي تحقيق توصيفي (غير آزمايشي) تحقيق همبستگي است. در اين نوع تحقيق رابطه ميان متغيرها بر اساس هدف تحقيق تحليل ميگردد.
تحقيقات همبستگي را ميتوان بر حسب هدف به سه دسته تقسيم كرد:
الف) مطالعه همبستگي دو متغيري،
ب) تحليل رگرسيون،
ج) تحليل ماتريس همبستگي يا كواريانس.
در مطالعات همبستگي دو متغيري، هدف بررسي رابطه دو به دو متغيرهاي موجود در تحقيق است.
در تحليل رگرسيون، هدف پيش بيني تغييرات يك يا چند متغير وابسته (ملاك) با توجه به تغييرات متغيرهاي مستقل (پيش بين) است. در بعضي بررسي ها از مجموعه همبستگي هاي دو متغيري متغيرهاي مورد بررسي در جدولي به نام ماتريس همبستگي يا كواريانس استفاده ميشود.
از جمله تحقيقاتي كه در آن ها ماتريس همبستگي يا كواريانس تحليل مي شود، تحليل عاملي و مدل معادلات ساختاري است.
در تحليل عاملي هدف تلخيص مجموعه اي از داده ها يا رسيدن به متغيرهاي مكنون (سازه) و در مدل معادلات ساختاري آزمودن روابط ساختاري مبتني بر نظريه ها و يافته هاي تحقيقاتي موجود است. {برو به فهرست}
در زير با تفضيل بيشتر هر يك از موارد فوق مورد بحث قرار ميگيرد.
1- ضریب همبستگی (تحقيق همبستگي دو متغيري)
در اين گونه تحقيقات هدف تعيين ميزان هماهنگي تغييرات دو متغير است. {برو به فهرست}
براي اين منظور بر حسب مقياس هاي اندازه گيري متغيرها، شاخص هاي مناسبي اختيار ميشود. از آن جا كه در اكثر تحقيقات همبستگي دو متغيري از مقياس فاصله اي با پيش فرض توزيع نرمال دو متغيري براي اندازه گيري متغيرها استفاده مي شود، لذا ضريب همبستگي محاسبه شده در اين گونه تحقيقات ضريب همبستگي گشتاوري پيرسون يا به طور خلاصه ضريب همبستگي پيرسون است.
1-الف- ضریب همبستگی پیرسون در قالب یک مثال
به عنوان مثالي از تحقيق همبستگي دو متغيري به تحقيقي از اين نوع در اينجا اشاره ميشود:
پژوهشگران براي آزمودن رابطه ”اسنادهاي دروني و باثبات“ با متغير ”احساس لياقت“ در عملكردهاي موفق و ناموفق فرضيه هايي را مورد آزمون قرار دادند و براي اين امر از ضرايب همبستگي پيرسون استفاده كردند. نمره مثبت اسناد مركز عليت نشانگر اسنادهاي دروني و نمره منفي آن نشانگر اسنادهاي بيروني بود. نمره مثبت اسناد ثبات نشانگر اسنادهاي باثبات و نمرات منفي آن نشانگر اسنادهاي بي ثبات بود.
فرضيه هاي تحقيق عبارت بودند از:
فرضيه 1: احساس لياقت با اسنادهاي دروني و باثبات براي عملكردهاي موفق همبستگي مثبت دارد.
فرضيه 2: احساس لياقت با اسنادهاي دروني و باثبات براي عملكردهاي ناموفق همبستگي منفي دارد.
در اين تحقيق متغيرهاي مورد بررسي به شرح زير است:
1-احساس لياقت، 2-عملكرد در آزمون، 3-اسناد مركز عليت براي عملكرد ناموفق، 4-اسناد باثبات براي عملكرد ناموفق، 5-اسناد مركر عليت براي عملكرد موفق و 6-اسناد ثبات براي عملكرد موفق.
بايد توجه داشت كه نمره مثبت اسناد مركز عليت نشانگر اسنادهاي دروني و نمره منفي آن نشانگر اسنادهاي بيروني بود. نمره مثبت اسناد ثبات نشانگر اسنادهاي باثبات و نمرات منفي آن نشانگر اسنادهاي بي ثبات بود.
به طور جزئی تر فرضيات تحقيق عبارت است از:
1- در عملكردهاي موفق، احساس لياقت با اسناد دروني همبستگي مثبت دارد.
2- در عملكردهاي موفق، احساس لياقت با اسنادهاي با ثبات همبستگي مثبت دارد.
3- در عملكردهاي ناموفق، احساس لياقت با اسناد دروني همبستگي منفي دارد.
4- در عملكردهاي ناموفق، احساس لياقت با اسنادهاي با ثبات همبستگي منفي دارد.
ضرايب همبستگي اين متغيرها در جدول زير داده شده است و معني داري اين ضرايب همبستگي با يك يا دو ستاره مشخص شده است.
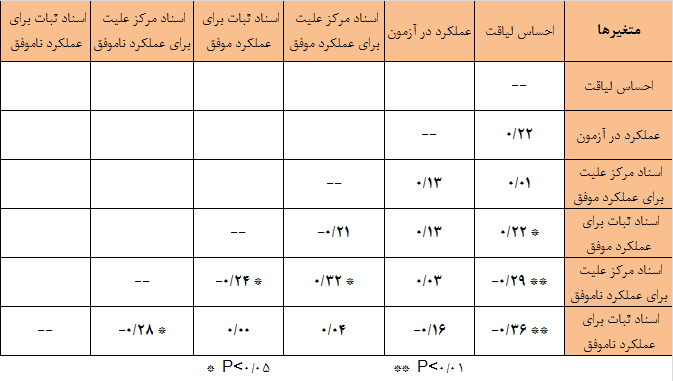
جدول فوق ضرايب همبستگي متغيرهاي اندازه گيري شده در بررسي رابطه هاي اسنادهاي دروني و باثبات با احساس لياقت را نشان می دهد.
1-ب- تحلیل ضریب همبستگی پیرسون و آزمون فرضیه
در مثال فوق با توجه به معني دار بودن برخي از ضرايب همبستگي ملاحظه ميشود كه فرضيه 1 كه به رابطه احساس لياقت با اسنادهاي باثبات در عملكردهاي موفق مربوط است تاييد ميگردد. (r=0.22 , P<0.05). فرضيه 3 و 4 محقق كاملا تاييد مي شود، زيرا همبستگي احساس لياقت با اسناد دروني و باثبات براي عملكردهاي ناموفق منفي و معني دار است (r=-.029 , P<0.05) و (r=-0.36 , P<0.01). {برو به فهرست}
پژوهشگران با توجه به نتايج به دست آمده از همبستگي هاي دو متغيري به آزمودن فرضيه هاي ياد شده پرداخته اند.
2- تحليل رگرسيون
در تحقيقاتي كه از تحليل رگرسيون استفاده مي شود، هدف معمولا پيش بيني يك يا چند متغير ملاك از يك يا چند متغير پيش بين است. چنانچه هدف پيش بيني يك متغير ملاك از چند متغير پيش بين باشد از مدل رگرسيون چندگانه استفاده ميشود.
در صورتي كه هدف، پيش بيني همزمان چند متغير ملاك از متغيرهاي پيش بين يا زير مجموعه اي از آنها باشد از مدل رگرسيون چند متغيري استفاده ميشود. {برو به فهرست}
در تحقيقات رگرسيون چندگانه هدف پيدا كردن متغيرهاي پيش بيني است كه تغييرات متغير ملاك را چه به تنهايي و چه مشتركا پيش بيني كند.
2-الف- روشهای ورود متغیرهای مستقل در مدل رگرسیون
ورود متغيرهاي پيش بين (متغیرهای مستقل) در تحليل رگرسيون به شيوه هاي گوناگون صورت ميگيرد. در اين جا سه روش اساسي مورد بحث قرار ميگيرد:
الف) روش همزمان،
ب)روش گام به گام،
ج) روش سلسله مراتبي.
روش رگرسیون همزمان
در روش همزمان تمام متغيرهاي پيش بين با هم وارد تحليل ميشود.
رگرسیون گام به گام
در روش گام به گام اولين متغير پيش بين بر اساس بالاترين ضريب همبستگي صفرمرتبه با متغير ملاك وارد تحليل ميشود. از آن پس ساير متغيرها پيش بين بر حسب ضريب همبستگي تفكيكي (جزئي) و نيمه تفكيكي (نيمه جزئي) در تحليل وارد ميشود. در اين روش پس از ورود هر متغير جديد ضريب همبستگي نيمه تفكيكي يا تفكيكي ، تمام متغيرهايي كه قبلا در معادله وارد شده اند به عنوان آخرين متغير ورودي مورد بازبيني قرار ميگيرد و چنانچه با ورود متغير جديد معني داري خود را از دست داده باشد، از معادله خارج ميشود. به طور كلي در روش گام به گام ترتيب ورود متغيرها در دست محقق نيست.
رگرسیون سلسله مراتبی
در روش سلسله مراتبي ترتيب ورود متغيرها به تحليل بر اساس يك چارچوب نظري يا تجربي مورد نظر محقق صورت ميگيرد. به عبارت ديگر پژوهشگر شخصا درباره ترتيب ورود متغيرها به تحليل تصميم گيري ميكند. اين تصميم گيري كه قبل از شروع تحليل اتخاذ ميشود ميتواند بر اساس سه اصل عمده زير باشد:
– رابطه علت و معلولي.
– رابطه متغيرها در تحقيقات قبلي.
– ساختار طرح پژوهشي (براي مثال در طرح هاي عاملي ابتدا اثرهاي اصلي و سپس اثرهاي متقابل آنها وارد تحليل ميشود).
از آن جا كه روش تحليل رگرسيون سلسله مراتبي با توجه به چارچوب نظري يا تجربي وپژه اي صورت مي گيرد، در تحقيقات علوم رفتاري از اهميت خاصي برخوردار است. لازم به تذكر است كه براي اين گونه تحقيقات آشنايي با روشهاي آماري تحليل رگرسيون الزامي است. {برو به فهرست}
قابل ذکر است این مرکز آماری آماده ارائه مشاوره و یا انجام تحلیل رگرسیون می باشد. چنانچه موردی هست از طریق شبکه های اجتماعی ذکر شده در پایین صفحات سایت با ما تماس بگیرید.
3- تحليل ماتريس كواريانس يا همبستگي
روش تحلیل عاملی چیست؟
در مواقعي كه محقق از همبستگي مجموعه اي از متغيرها بخواهد تغييرات متغيرها را در عامل هاي محدود تر خلاصه كند يا خصيصه هاي زير بنايي يك مجموعه از داده ها را تعيين نمايد از روش تحليل عاملي استفاده ميكند.
روش مدل معادلات ساختاري چیست؟
در صورتي كه محقق بخواهد مدل خاصي را از لحاظ روابط متغيرهاي تحت بررسي بيازمايد، از روش مدل معادلات ساختاري استفاده ميكند. {برو به فهرست}
براي هر دو منظور فوق لازم است كه ماتريس كواريانس متغيرهاي اندازه گيري شده تحليل شود.
3- الف) تحليل عاملي
ماتريس كواريانس در تحليل عاملي با دو هدف متفاوت ميتواند تحليل شود: ”هدف اكتشافي“ و ”هدف تاييدي“.
چنانچه هدف اكتشافي باشد دو رويكرد متفاوت وجود دارد:
1- تعيين سازه يا متغيرهاي مكنون در يك حوزه از عملكرد كه به وسيله ابزارهاي اندازه گيري خاصي ارزيابي شده اند. اين هدف از طريق روش ”عامل مشترك“ ميسر ميشود.
2- تلخيص داده ها: در اين روش متغيرهاي به دست آمده به صورت شاخص هاي خلاصه تري در ميآيند. تلخيص داده ها معمولا از طريق روش ”مولفه هاي اصلي“ صورت ميگيرد.
در صورتي كه محقق درباره تعداد عامل هاي خصيصه ها فرضيه اي نداشته باشد، تحليل عاملي اكتشافي (efa) و در صورتي كه فرضيه موجود باشد تحليل عاملي تاييدي (cfa) ناميده ميشود.
آموزش تحلیل عاملی
برای دریافت آموزش ویدئویی تحلیل عاملی تاییدی با نرم افزار لیزرل (مرتبه اول و مرتبه دوم)، لینک آموزش تصویری CFA را کلیک نمایید.
براي توضيحات بيشتر درباره تحليل عاملي مي توانيد به مقاله ” تحليل عاملي با نرم افزار ليزرل Lisrel” مراجعه نماييد.
همچنين مي توانيد مقالات {برو به فهرست}
تحليل عاملي (روشي براي خلاصه سازي داده ها)
کاربردهاي تحليل عاملي (Factor Analysis: CFA – EFA)
را از سايت های اين مجموعه تخصصی آماري ملاحظه نماييد.
3-ب) مدل معادلات ساختاري
در تحقيقاتي كه هدف، آزمودن مدل خاصي از رابطه بين متغيرها است، از تحليل مدل معادلات ساختاري يا مدل هاي علّي استفاده ميشود.
در اين مدل داده ها به صورت ماتريس هاي كواريانس يا همبستگي درآمده و يك مجموعه معادلات رگرسيون بين متغيرها تدوين ميشود. چنانچه در مدل براي هر متغير از بيش از يك نشانگر استفاده شود، مدل شامل مولفه اندازه گيري نيز ميشود.
تحليل مدل معادلات ساختاري برآوردهايي از پارامترهاي مدل (ضرايب مسير و جملات خطا) و چند شاخص نيكويي برازش فراهم مي آورد.
امكان تحليل مدل هاي علّي پس از نگارش نرم افزارهايي از جمله Lisrel و EQS صورت گرفته است. اين نرم افزارها به تدريج كامل تر و پيچيده تر شده اند.
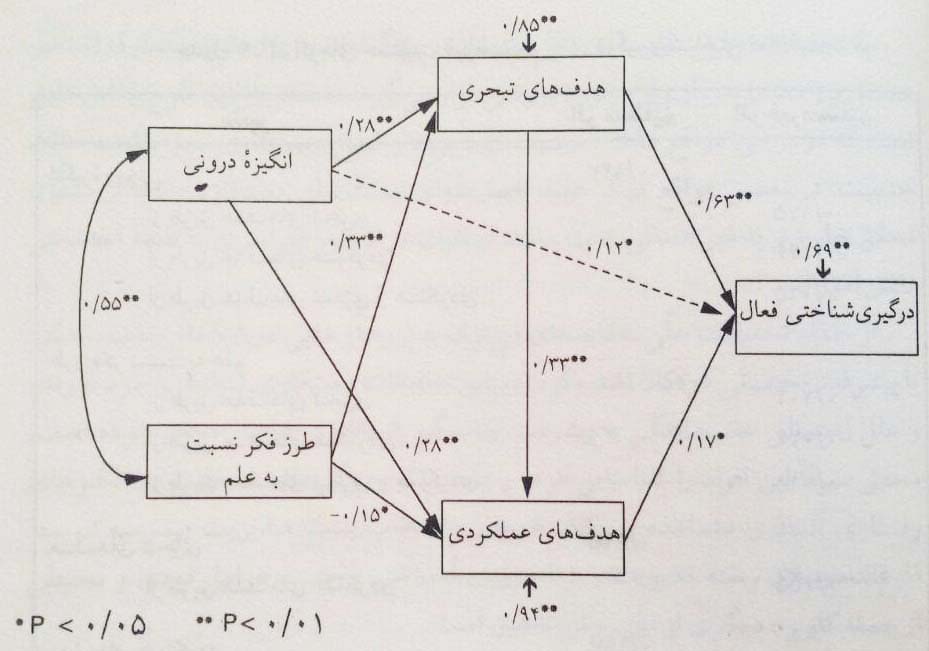
مثالی از نمودار مسیر مدل ساختاری
به طور کلی مدل های ساختاری به منظور بررسی اثرهای مستقیم و غیر مستقیم متغیرها در جهت شناخت روابط علی محتمل مورد استفاده قرار می گیرد. تصویر زیر یک نمونه نمودار مسیر مدل ساختاری برآورد شده را نشان می دهد:
سایت های تخصصی معادلات ساختاری
براي دريافت اطلاعات بيشتر در مورد مدل سازي معادلات ساختاري مي توانيد و مطالعه مقالات متنوع به سايت ويژه مدل سازي و مدل يابي معادلات ساختاري، برازش مدل، تحليل مسير و تحليل عاملي با نرم افزار Lisrel اين مرکز به آدرس :
مراجعه نماييد. از صفر تا صد معادلات ساختاري با نرم افزار لیزرل را در سايت فوق مطالعه خواهيد نمود.
همچنين اين مرکز آماري به جهت ورود تخصصي و هدفمند به مباحث فني و آماري ، وب سايتي را نيز به مدل سازي معادلات ساختاري با روش کمترين مربعات جزئي يا همان PLS اختصاص داده است. این سایت که بر نرم افزار جديد اسمارت پي ال اس (Smart Pls) تمرکز دارد به آدرس زير می باشد:



با سلام خدمت مدیر سایت. میخواستم بدونم نرم افزار آماری Interaction که معمولا برای بررسی اثرات متغیر تعدیل گر استفاده میشه. با تشکر
سلام.
با این نرمافزار آشنایی نداریم.
برای بررسی متغیر تعدیلگر از نرم افزار اسمارت پی ال اس استفاده می کنیم. سایت مخصوص نرم افزار smart pls ما و مقالات و مطالب آنرا را ببینید:
https://www.smartpls.ir/
با سلام و وقت بخیر
1. در صورتی که یک متغیر مستقل و چند متغیر وابسته داشته باشیم از چه روش رگرسیونی باید استفاده کنیم؟
2. آیا قبل از مدل معادلات ساختاری با استفاده از Amos و Pls حتما باید تحلیل رگرسیون رو انجام بدیم؟ یا اینکه می شود بعد از ضریب پیرسون به سراغ مدل معادلات ساختاری رفت؟
با تشکر فراوان.
سلام
1- از رگرسیون خطی ساده باید استفاده کرد. یعنی باید برای هر متغیر وابسته یک مدل رگرسیونی داشته باشیم. در اصل از مدلسازی معادلات ساختاری باید استفاده کرد نه رگرسیون.
2- لازم نیست قبل از استفاده از نرم افزار ایموس یا پی ال اس رگرسیون و همبستگی استفاده کرد. چون این دو نرم افزار بر اساس همبستگی کانونی متغیر وابسته را به وسیله متغیر مستقل پیش بینی می کنند (نه بر اساس همبستگی پیرسون که در رگرسیون استفاده می شود) و ضرایب بتا و همبستگی را گزارش می دهند.
این مرکز تحلیل آماری وب سایتهایی دارد که به صورت خاص (صفر تا صد) بر نرم افزارهای لیزرل و ایموس، و همچنین بر نرم افزار اسمارت پی ال اس تمرکز می کند. روی لینکها کلیک تا این وب سایتها را ببینید. در این زمینه (معادلات ساختاری و تحلیل مسیر) نیز ارائه خدمات داریم
سلام اگر چند کتغیر وابسته و چند متغیر مستقل داشتم هم باز میتونم از رگرسیون خطی برم؟
سلام. چندین مدل رگرسیون با متغیرهای وابسته متفاوت دارید یا اینکه همزمان می خواهید رگرسیون چند متغیر مستقل را بر روی چند متغیر وابسته بسنجید؟ اگر مورد اول است، می توانید رگرسیون خطی استفاده کنید. و اگر مورد دوم است، از معادلات ساختاری استفاده نمایید.
بد نیست شما مبحث مدل سازی معادلات ساختاری را نیز مد نظر داشته باشید و مطالعه کنید: http://www.lisrel.ir
سلام، خداقوت. میشه لطفا بگید اگر متغیروابسته ام نرمال و یکی از متغیرهای مستقلم غیرنرمال ودیگری نرمال است. میشه پاسخ بدید که ایا می تونم از ازمون رگرسیون خطی در حالت اینتر استفاده کنم یا خیر؟ نمونه ی آماری 150 نفر است. با تشکر 🙂
سلام، وقت بخیر
در رگرسیون در اصل مهم این است که باقیمانده ها (جملات اخلال) پس از اجرای مدل دارای توزیع نرمال باشند. شما باقیمانده ها را بررسی کنید اگر نرمال بودند مدل از این نظر برازش خوبی دارد.
از زاویه دیگر باید گفت نرمال بودن متغیر وابسته اهمیت دارد نه متغیرهای مستقل. بنابراین شما می توانید از رگرسیون خطی استفاده کنید. نرمال بودن باقیمانده ها را نیز چک کنین.
سلام وقتتون بخیر
با موضوع “پیش بینی شدت درد بر اساس سبک های اسنادی و ابرازگری هیجانی در زنان مبتلا به سرطان سینه در شهر تهران با نقش واسطه ای سبک زندگی”
الان سبک زندگی نقش متغیر میانجی داره اینجا درسته؟
میتونم از رگرسیون استفاده کنم؟
سلام. سبک زندگی میانجی هست. شدت درد وابسته سبک اسنادی و ابرازگری هیجانی مستقل.
رگرسیون با SPSS میشه استفاده کرد. روش مدلسازی معادلات ساختاری بهتر هست
باسلام
نرمال بودن داده ها در متغیرهای مستفل و وابسته یکی از پیش شرطهای رگرسیون است.
سلام. نه. نرمال بودن باقیمانده ها یکی از پیش شرطهای رگرسیون است. در کتابهای آماری اینگونه آمده
سلام
وقت بخیر
چند عدد سوال در مورد خروجی correlation در SPSS دارم اگه جواب بدین ممنون می شم
1- ضریب همبستگی و آماره آزمون همبستگی را چگونه میتوان از آن بدست آورد ؟
2-رابطه خط رگرسیون را چگونه می توان از آن بدست آورد ؟
3-اگه میشه یه توضیحی هم در مورد موارد داخل جدول بدین بهم
با سپاس و تشکر از سایت بینظیرتون
سلام؛ متشکر
1- ضریب همبستگی و آماره آزمون دو جزء مهم از خروجی آزمون همبستگی در spss است که براحتی در خروجی دیده می شود. ضریب همبستگی عددی بین -1 و 1 است. آماره آزمون هم در خروجی گزارش می شود با نام انگلیسی statistic.
2- برای بدست آوردن رابطه خط رگرسیون می بایست آزمون رگرسیون را اجرا کنید و در باکس مربوطه، متغیر وابسته و متغیرهای مستقل را قرار دهید. این رابطه در خروجی آزمون همبستگی نیست.
3- اینجا نمی توان بیشتر از این وارد جزئیات شد. پیشنهاد می شود خروجی را گرفته و داخل فایل ورد قرار دهید و از طریق ایمیل یا پیام رسان ها برای ما بفرستید و سوال تان را طرح تا همکاران ما بررسی کنند. اگر طولانی نباشد جواب می دهند و اگر جزئیات زیاد باشد شما را به خریداری محصول مشاوره راهنمایی می کنند. با پرداخت مبلغ کمی می توانید از مشاوره تلفنی و پیامی ما استفاده کنید.
با سلام و خسته نباشید
چنانچه در پژوهش چند متغیر مستقل و چند متغیر وابسته داشته باشیم از کدام روش رگرسیون باید استفاده کنیم؟
سلام. از روش مدلسازی معادلات ساختاری می بایست استفاده نمایید که با نرم افزارهایی مثل لیزرل و اسمارت پی ال اس قابل انجام است. رگرسیون اینجا جواب نمی دهد. سایت اسمارت پی ال اس ما:
http://www.smartpls.ir
با توجه به مشکلات مختلفی که تحلیل رگرسیونی دارد، در حال حاضر هیچ ژورنال معتبری در تحلیل فرضیات علی ، تحلیل رگرسیونی را قبول نمی کند.
با سلام و تشکر فراوان از اطلاعات و مطالب مفید آماری شما
سوالی که خدمتتون داشتم اینه که اگر در داده ها و جداول آماری که از روش رگرسیون همزمان استفاده شده است،مقدار sig برای مدل رگرسیون همزمان بیشتر از ۰/۰۵بشود(در یکی از جداول پژوهش من رگرسیون کلی مدل همزمان برای مولفه های پیش بین و متغیر ملاک ۰/۰۶۸شده که بنابراین معنی دار نیست)اما در میان ۳مولفه پیش بین ،sigیکی از مولفه ها معنی دار(۰/۰۰۸) است.در این حالت برای تحلیل و تفسیر باید چگونه تحلیل کرد؟به بیان دیگر باید گفت مثلاً متغیر مستقل(متغیر پیش بین) من که در مجموع شامل ۳ زیر مقیاس است قادر به پیش بینی متغیر ملاک نمی باشد…
و یا اینکه باید گفت که مثلاً زیر مقیاس دوم معنی دار است چون sig برابر ۰/۰۰۸ شده ، ولی چون sig کلی مدل رگرسیون همزمان معنی دار نیست(۰/۰۶۸)بنابراین متغیر های پیش بینقادر به پیش بینی متغیر ملاک نمی باشند.
خواهشمندم در صورت امکان راهنمایی بفرمایید
با تشکر فراوان
سلام و تشکر؛
آنطور که متوجه شدم وضعیت شما چنین است: مدل رگرسیون شما در حالت کلی معنی دار نیست اما در خصوص یک متغیر خاص، ضریب آن معنی دار است.
در این حالت نمی توانید به نتایج یک متغیر خاص استناد نمایید زیرا مدل در حالت کلی معنی دار نیست. با تغییر مدل، ابتدا به مدلی برسید که مقدار sig آن در حالت کلی معنی دار باشد،سپس به تفسیر نتایج برای هر متغیر بپردازید.
ببخشيد من هم در پژوهشم به همين مشكل برخورد كردم، يعني تمامي متغيرها sig معنادار دارند بجز مدل ثابت رگرسيون! فرموديد مدل رو تغيير بديم ،ميشه بفرماييد چطور ميشه اين كارو كرد و أيا بدون تغيير مدل نميتوان به معنادار بودن sig متغيرها استناد كرد؟
یک نکته را دقت داشته باشید. سوال جناب فرزادفر با شما تفاوت دارد. ایشون مدل شان در حالت کلی معنی دار نبود، اما شما ظاهرا متغیر ثابت (عرض از مبدا یا c) معنی دار نیست. اگر اینطوری است مشکلی وجود ندارد.
اما اگر در کل مدل معنی دار نیست، یا باید داده ها را بررسی کنید و مقادیر پرت را شناسایی و حذف کنید یا اینکه مدل را تغییر دهید. بهرحال مدلی که معنی دار نیست، کاریش نمیشه کرد.
سلام میخواستم ببینم امکانش هست بخش تحلیل آماری رساله را انجام بدهید.
سلام. بله خدمت شما هستیم. از کانال های ارتباطی ذکر شده در پایین سایت با ما تماس بگیرید. بعد از بررسی مستندات ارسالی شما، قیمت و زمان اعلام خواهد شد.
سلام. تو رو خدا بمن بگين اين تحليل با نرم افزار R چيه ك يه موسسه ب اسم “…” بمن ميگن 3500تومن فقط برا فصل 4 ازت ميگيريم!!! انصافه آخه؟ چرا بعضي موسسات وجدانشون يادشون رفته؟ چرا فكر نميكنن خدايي هم هست؟؟؟ منم نرم افزارهاي spss، جي متريك، ليزرل، باي لوگ و مولتي لوگ بلدم پاشم بگم آره چون طرف وقتش محدوده خداتومن قيمت بگم بهش چون مجبوره ميده و بعد لذت ببرم ك پول حسابي ازش گرفتم بابت كاري ك واقعا بيشتر از 1 ساعت وقت نميبره؟!
واقعا تاسف برانگيزه
سلام؛ از اعلام نظر شما در سایت متشکرم.
نرم افزار آر یک نرم افزار اپن سورس آماری است که حرفه ای های آماری از آن استفاده می کنند، یعنی اکثرا خود دانشجویان و اساتید رشته آمار از آن استفاده می کنند و مورد استفاده سایر رشته ها نیست.
جالب است بدانید معمولا افرادی قیمت های نجومی می گیرند که اصلا تخصص این کار را هم ندارند!
ضمنا بهتر است تحلیل آماری خود را به مراکزی بدهید که شخصیت حقوقی ثبت شده بوده و دارای آدرس و شماره تلفن ثابت باشند و به یک ارتباط تلگرامی با شماره ایرانسل اکتفا ننمایید!
سلام وقت به خیر.
تحلیل رگرسیون همزمان چندگانه دقیقا چیه؟ و معادل انگلیسیش چی میشه؟
ممنون میشم پاسخ بدید
سلام. برا ما ك روانشناسي هستيم اينجوري گفتن: وقتي چندتا متغير داشته باشين و قرار باشه پيش بيني كنين مسيرشم اينه:
analyze–>regresion–>linear–>dependent(motaghayer vabasteh), independents(motaghayerhaye mostaghel)
بعد اون پايين ماها method رو گام ب گام انتخاب ميكنيم تا ببينيم كدوم متغير قدرتش بيشتره
برا ماها ك اينجوري بوده. اميدوارم كمك كننده باشه.
سلام. رگرسیون همزمان در نرم افزار اس پی اس اس همان رگرسیون خطی هست که تعداد متغیرهای مستقل بیشتر از یکی هست.
در نرم افزار اس پی اس اس این امکان نیست که چند رگرسیون چندگانه رو باهم انجام داد و باید تک تک خروجی گرفت.
ولی اگر بخواین همزمان بسنجید باید از روش مدل یابی معادلات ساختاری و نرم افزار هایی نظیر لیزرل و یا اسمارت پی ال اس استفاده کنید.
معادل انگلیسی مدل یابی معادلات ساختاری
structural equation model (SEM)
سایت های ویژه مدل سازی معادلات ساختاری این مرکز را ملاحظه نمایید: lisrel.ir – smartpls.ir
ارسال اطلاعات کار از چه طریق؟
آدرس ایمیل رو بفرمایید لطفا
ایمیل: etminan@iran.ir
واتس آپ یا سروش با شماره: 09198180991 (خانم دهقان)
با سلام. بنده در پیدا کردن روش صحیح اماری در spss و تحلیل آن برای کاره پایان نامم به مشکل برخوردم. ممنون میشم راهنمایی بفرمایید.
در پژوهش ما تحت عنوان:
تاثیر هشت هفته تمرین مقاومتی و مصرف استروئیدهای انابولیک بر igf1 و قدرت عضلانی مردان جوان.
40 مرد در چهار گروه (1: گروه تمرین مقاومتی 2: گروه مصرف استروئید 3: گروه تمرین + مصرف استروئید 4: گروه کنترل) به صورت مساوی تقشیم شدند.
به صورتی که اندازه گیریهای متغیر های وایسته (igf1 و قدرت عضلانی) قبل از انجام پژوهش ( پری تست) و بعد پژوهش (پست تست) انجام پذیرفت.
فرضیه ها و سوال ها:
1: هشت هفته تمرین مقاومتی موجب افزایش hgf1 مردان میشود؟
2: هشت هفته تمرین مقاومتی موجب افزایش قدرت مردان میشود؟
3: هشت هفته مصرف استروئید انابولیک موجب افزایش قدرت مردان میشود؟
4: هشت هفته مصرف استروئید انابولیک موجب افزایش igf1 مردان میشود؟
5: ایا با افزایش igf1 میزان قدرت بدنی مردان افزایش یافته است؟ ( تاثیر یک متغیر وابسته بر یک متغیر وابسته دیگر در هر چهار گروه).
مخصوصا فرضیه 5 که تاثیر یک متغیر وابسته بر اون یکی متغیر وابسته بسیار مهم است (یعنی ایا با افزایش میزان igf1 قدرت عضلانی نیز افزایش یافته است؟).
آزمون جامعی وجود دارد که به تمام سوال ها یک جا پاسخ بدهد؟ اگر نیست چگونه باید تحلیل شود؟
لطف بزرگی میکنید اگر بنده را راهنمایی بفرمایید.
با سلام. برا بچه هاي فيزيولوژي ورزشي اگر دادهها توزیع نرمال باشه t زوجی استفاده میشه اما اگر توزیع نرمالی نباشه از آزمون ویلکاکسون. البته دوست من ك فيزيولوژي ورزشي بود اينجوري انجام داده بود راهنماشم اوكي كرد. اميدوارم كمك كننده باشه
سلام.خیلی ممنون از شما. ولی تی زوجی یا همون تی وابسته رو وقتی میگیرم که یک گروه را در دوزمان بخواهیم تحلیل کنیم. ولی وقتی بیش ار یک گروه باشد ازمون های جامع تر مثل آنوا ها میتونن کار ساز تر باشن.
آره ديگه مال دوست من هم يه گروه بود برا تردميل و افزايش فشار خون و اينا بود رو بچه ها قبل رفتن رو تردميل و بعد رفتن رو تردميل از همين تي رفته بود. استادشم تاييد كرد. من فقط عنوانتون رو خونده بودم گروه بنديش نگاه نكردم. حالا استادم عصر دم دستم هستش ازش ميپرسم اگر كمكي كرد براتون ميذارم.
خیلی ممنون میشم از شما… من سوال 5 برام خیلی مهمه… یعنی بررسی تاثیر یک متغبر وابسته بر اون یکی متغیر وابسته.. میخاستم بدونم انالیز واریانس ها یا ریپیدد میجر میتونه این رو هم اندازه گیری بکنه یا باید از ازمون دیگه ای به صورت مجزا استفاده بکنم… ممنونم از شما
با سلام من متاسفانه اون لحظه ب نت دسترسي نداشتم. ب استادم گفتم وقتي 4 گروه داريم قبل انجام آزمايشي ازشون تست ميگيريم بعد دوباره بعد انجام آزمايش هم همون تست ميگيرم و ميخوايم ببينيم افزايش مشاهده شده يا نه چكار ميكنيم؟ گفت اگر يك متغير بر يك متغير ديگه باشه آنووا اما اگر چند متغير باشه MANOVA حالا من متن خودتون براش ميفرستم ك جواب دقيقي بده.
سلام خسته نباشید
من در حال انجام یک تحقیق هستم و سولاتی دارم ممنون می شم پاسخ بدید
1- در تحقیق من دو متغیر مستقل و یک متغیر وابسته وجود دارد این اشتباه می باشد ؟
1- نمونه من غیر نرمال است و دارم از آزمون اسپیرمن استفاده می کنم آیا می توانم از رگرسیون خطی هم استفاده کنم ؟
ایا در رگرسیون خطی از متغیرهای صفر و یکی هم می توان استفاده کرد ؟ یعنی متغیر اسمی
سلام؛ 1- درست است. 2- به دلیل غیر نرمال بودن از رگرسیون خطی نمی توانید استفاده کنید.
کلا وقتی داده ها صفر و یک است چون معمولا توزیع نرمال ندارند نمی توانید رگرسیون استفاده کنید. اما اگر استفاده کردید و نشان دادید باقیمانده های مدل دارای توزیع نرمال است، درست است و مشکلی نیست
باسلام
1- نمونه غیر نرمال نیست و داده ها نرمال یا غیر نرمال هستند.
2- هر فرضیه یک آزمون آماری درست دارد. بنابراین باید دید که فرضیه این دوستمون چیه. اگر فرضیات رابطه ای باشد باید با توجه به مقیاس متغیرها آزمون صحیح همبستگی و احیانا آزمون تعقیبی مناسب ار بکاربرد.
3- از پیش فرض های رگرسیون نرمال بودن متغیرهای مستقل و وابسته است. بنابراین اگر فرضیات ایشان علی باشد اصلا اجازه استفاده از رگرسیون خطی را ندارند. حتی از رگرسیون لجستیک هم نمی توانند استفاده کننده وقتی که نرم افزاری مانند mplus وجود دارد.
سلام مجدد
یه سوال مهم دیگه
ایا باید در وارد کردن داده های پرسشنامه در نرم افزار SPSS سوالاتی که مفهوم منفی دارند را برعکس رتبه بندی کنیم و وارد کنیم ؟
سلام؛ بله برعکس امتیاز دهی کنید سوالات منفی را. در نهایت هنگام تحلیل باید سوالات هم جهت باشند تا تحلیل ها درست باشد
باعرض سلام و تشکر از سایت مفید و ارزشمندتان
یک سوال داشتم: اینکه در رگرسیون چند متغیره به روش همزمان، آیا از روی مثبت و یا منفی بودن ضرایب همبستگی اسپیرمن بین متغیرهای پیش بین و ملاک، می توان مثبت و منفی بودن ضرایب استاندارد شده ، استاندارد نشده و ضریب B را حدس زد؟ اگر چندین رابطه همبستگی بین متغیرهای پیش بین و ملاک منفی بوده باشد، آیا می توان در ارتباط با اینکه حداقل یکی از ضرایب ذکرشده در بالا منفی خواهد بود، نتیجه گیری داشت؟
باتشکر از شما که وقت گرانبهای خود را به پاسخگویی به سوالات اختصاص می دهید.
سلام. وقتی می توانیم آزمون رگرسیون را انجام داده و نتایج آنرا ببینیم چرا باید بر اساس ضریب همبستگی استنباط داشته باشیم!
در پاسخ سوال شما تا حدودی بین نتایج ضریب همبستگی و ضرایب رگرسیون ارتباط هست ولی قطعی فکر نکنم بتوان صحبت کرد. بهرحال در رگرسیون، سایر متغیرهای حاضر در مدل نیز بر روابط تاثیر می گذارند.
سلام. من موضوع مقاله م ایجاد مشارکت اجتماعی با هدف افزایش خلاقیت در کودکان در فضاهای فرهنگی هست.
و فرضیه هام:
• به نظر میرسد با تغییر در عوامل کالبدی محیط معماری میتوان در رشد خلاقیت کودکان موثر بود.
• به نظر میرسد می توان با طراحی فضاهای فرهنگی تعامل اجتماعی بین کودکان را به منظور افزایش خلاقیت، استحکام بخشید.
من از تمام مطالعاتی که در مبانی نظری گردآوری کردم یکسری مولفه یا شاخصه هایی رو در نظر گرفتم
و با در نظر گرفتن تمام مواردی که در نمونه موردی ها رعایت شده یا نشده بود به یه جدول رسیدم که تمام مولفه های موثر بر افزایش خلاقیت و مشارکت اجتماعی رو در اون آوردم.
اما احساس میکنم این کافی نیست و نیاز به پرسشنامه و انجام مطالعات میدانی داره.
پرسشنامه مو به صورت زیر طراحی و با کمک تعدادی از مربی یا معلم های مهد و فرهنگسراها پر کردم. اما حالا نمیدونم از چه روشی برای تحلیل و آزمون فرضیاتم باید استفاده کنم؟
سوالمم بصورت نمونه بیان میکنم(که با 5 درجه بررسی شده است: خیلی کم- کم- متوسط- زیاد- خیلی زیاد)
رنگ به چه میزان در افزایش خلاقیت تاثیر داره؟
ممنون میشم راهنماییم کنین.
سلام؛ قطعا با داشتن پرسشنامه و تحلیل نتایج آن کار شما ارزش علمی بیشتری خواهد داشت.
اینجا فرصت نیست وارد جزئیات کار شما شویم. پرسشنامه و فرضیات را برای ما ارسال نمایید و اعلام نمایید که قصد دریافت مشاوره دارید تا همکاران ما هماهنگی بین پرسشنامه و فرضیات را بررسی و آزمون آماری لازم را به شما اعلام نمایند.
سلام
کمترین اندازه نمونه تو مدل سلسله مراتبی خطی (HLM) برای فرد و گروه(خوشه) چقدره؟ تو مقالات جامعه شناسی کمترین مقدار قابل قبول برای گروه رو 30
عنوان کردن.
برای این مدل نهایت بتونم داده های 23 تا گروه(سطح فرد:شرکت و سطح گروه: صنعت) رو پیدا کنم(رشته حسابداری). آیا باز هم میشه از این مدل استفاده کرد؟
سلام؛ کلا در بحث رگرسیون تعداد داده کمتر از 30 تا معمولا کار جالبی بدست نمی آید. زیرا با تعداد داده کم استنباط خوبی نمی شود انجام داد. مگر اینکه همین تعداد داده ها دارای توزیع نرمال باشند.
یک نکته: معمولا داده های حسابداری به صورت پانل دیتا است و با نرم افزار ایویوز تحلیل می شود و نه نرم افزار spss. این سایت ما را مطالعه نمایید:
http://www.eviews-iran.ir
ممنون از پاسخگویی
من برای سطح گروه(سطح دوم) گفتم که کمتر از 30 هست وگرنه در سطح فرد(فرد) داده ها بیشتر از 150 است(منظور از سطح فرد شرکت و گروه تعداد صنایع مرتبط با سطح فرد).
برای Hierarchical linear model تو فضای مجازی یا کتاب های مرتبط با این مدل، هیچ جا ندیدم که حرفی از ایویوز زده باشن.و از این نرم افزار ها میشه استفاده کرد SAS, Stata, HLM, R, SPSS, و Mplus و براشون ویدئو آموزشی وجود داره.
تو این کتاب هم حرفی از ایویوز http://methods.sagepub.com/book/hierarchical-linear-modeling زده نشده.
چون یکی از متغیرها به صورت کیفی است، به همین دلیل در جمع آوری داده با محدودیت مواجه بودم.
پ.ن:تو این مدل مشکل نرمال نبودن داده ها رو نداریم.فقط نرمال بودن مقادیر خطا مهم است.
درسته.
Hierarchical linear model تحلیل فنی و خاصی است. در خصوص نرمال بودن هم صحبت شما را قبول دارم و در اصل هم در رگرسیون نرمال بودن مقادیر خطا مهم است نه نرمال بودن داده ها
با سلام و تشکر
من در مرحله پروپوزال نویسی هستم و هدف پژوهشم مدل یابی رابطه (غیر علی) دو سازه (چند بعدی) و کشف متغیر های تعدیل گر احتمالی هست، چون پژوهش های قبلی روابط متعارضی نشون دادند و حدس من وجود متغیر های تعدیلگر، یا وجود الگویی وابسته به ابعاد این دو متغیر هست.
با این توضیحات:
1- آیا طرح تحقیقم، مدل یابی ساختاری خواهد بود؟
2- در مورد روش تجزیه تحلیل و تحلیل داده، چی باید نوشت “بررسی شاخص های آمار توصیفی ( میانگین، انحراف معیار) و تحلیل عامل اکتشافی”؟
2- آیا لازمه اول مدل فرضی ارائه بدم و بعد اونو رد یا تایید کنم، یا برنامه ای هست که تمام احتمالات ممکن رو بررسی کنه و الگو ارائه بده؟
3- آیا ممکنه برخی از ابعاد دو سازه اصلی، یا مثلا “نسبت بین ابعاد هر یک از سازه ها” رو به شکلی به عنوان تعدیل گر اعلام و بررسی کنم؟
سلام. کار شما تحلیل عاملی اکتشافی و تاییدی هست. ولی این دو روش متغیر تعدیلگر رو مشخص نمی کنه.
بهتره که مدل داشته باشید و اون رو برازش بدید. چون هیچ نرم افزاری به شما مدل پیشنهاد نمیده
تشکر و سپاس فراوان
با سلام و خسته نباشید من یه سوال دارم
من دو تیمار داشتم یکی کشت مخلوط ک با bمشخص کرده بودم و یکیaک تنش بود و( در دوسطح نرمال و تنش آبی )بود
واضح تر بگم منظورم اینه که اگه ضریب همبستگی رد ب صورت کلی به دست بیارم در حالت تنش(آبی و نرمال).تیتر رو بنویسم ضریب همبستگی صفات تحت شرایط تنش؟؟؟و اگه بخوام سطوح رو تفکیک کنم بنویسم تیترو ضریب همبستگی صفات تحت تنش آبی و یه جدول دیگه ضریب همبستگی صفات تحت آبیاری نرمال؟ممنونم از راهنماییتون
سلام؛ حقیقتش خیلی متوجه سوال شما نشدم. اما چون گفتید تیمار و اینکه دو سطح داده دارید، به نظر می رسد از روش آنالیز واریانس در spss استفاده کنید بهتر است تا روش ضریب همبستگی
سلام . میشه با مثال بفرمایید چه زمان از تحلیل مسیر و چه زمان ار معادلات ساختاری استفاده می شود.ممنون
سلام. معادلات ساختاری زمانی استفاده می شود که متغیر مستقل و وابسته داخل مدل باشد و هر متغیر با چند سوال پرسشنامه سنجیده شده باشد. و
تحلیل مسیر زمانی استفاده می شود که متغیر مستقل و وابسته داخل مدل باشد و حداقل یک متغیر با یک سوال سنجیده شده باشد. البته اگر هر متغیر با چند سوال سنجیده شده باشد می توان هم از معادلات ساختاری استفاده کرد و هم از تحلیل مسیر.
با سلام و خسته نباشید
1- چنانچه در پژوهش چند متغیر مستقل و چند متغیر وابسته داشته باشیم از کدام روش رگرسیون باید استفاده کنیم؟
2- چنانچه دو متغیر پیش بین و چند متغیر ملاک داشته باشیم باید برای هر کدام رگرسیون مجزا بگیریم یا روشی برای انجام یک رگرسیون واحد وجود دارد؟
ممنون از سایت بسیار خوبتون و پاسخ دهی عالی و سرشار از احترامتون.
موید باشید
سلام. نظر لطف شماست.
اگر از اس پی اس اس استفاده می کنید باید برای هر متغیر وابسته رگرسیون جداگانه گرفته شود. (اگر یک متغیر مستقل وجود دارد رگرسیون ساده خطی و اگر چند متغیر مستقل وجود دارد رگرسیون خطی چندگانه استفاده می شود.)
با این حال نرم افزار های معادلات ساختاری نظیر لیزرل یا ایموس و یا اسمارت پی ال اس این توانایی را دارند که با استفاده از همبستگی کانونی همه رگرسیون ها را به صورت یک جا انجام دهند. این سایت ها مربوط به معادلات ساختاری بوده و متعلق به مجموعه ما هستند: lisrel.ir – smartpls.ir
سلام استاد
ببخشید من خودم مدل را در نرم افزار ایموس انجام دادم و خروجی هم گرفتم.
الان مشکل من این است که چطوری می توانم جدول اثرات غیر مستقیم را بنویسم. جدول اثرات مستقیم مشخص هستش. همون جدول اولی هستش. ولی برای اثرات غیر مستقیم نرمافراز ایموس فقط به صورت ماتریس خروجی میده.
میخوام جدول غیر مستقیم را مثل جدول مستقیم بنویسم ولی مقدار برآورد، مقدار استاندارد و مقدار خطای غیر مستقیم و مقدار cr غیر مستقیم چگونه محاسبه میشه.
پیشاپیش سپاس از توضیح کامل شما
سلام. باید در ایموس تیک ضرایب غیرمستقیم را بزنید.
ولی از آزمون سوبل هم می توانید استفاده کنید.
سپاس. تیک را می زنم ولی خروجی ایموس برای اثرات غیر مستقیم و اثرات کل به صورت جدول نیست. به صورت ماتریس است.
در حالیکه برای اثرات مستقیم همان ابتدای صفحه به صورت جدول گزارش داده است.
مشکل من نحوه ی گزارش اثرات غیر مستقیم و اثرات کل به صورت جدول است.
بهتر است یک محصول مشاوره تلفنی ما را خریداری نمایید (از بخش محصولات وب سایت) و با کارشناس خبره ما تلفنی صحبت و مساله خود را حل کنید. اینجا بیشتر نمی شود وارد جزئیات شد.
قبلش سوال خود را از طریق واتس آپ به شماره 09198180991 ارسال نمایید.
باسلام و تشكر از وقت گزاريتون
ميخواستم بدونم تفاوت رگرسيون سلسله مراتبي و گام به گام چيست و رگرسيون سلسله مراتبي كدام گزينه ي رگرسيون در spss است؟
باتشكر
سلام؛ رگرسیون سلسله مراتبی و رگرسیون گام به گام در متن این صفحه به روشنی توضیح داده شده است. گزینه step wise مربوط به رگرسیون گام به گام در نرم افزار spss است.
همانطور که در توضیحات این صفحه گفته شده است، در روش سلسله مراتبی خودتان تصمیم می گیرد که چه متغیرهایی را به ترتیب وارد مدل کنید و دستور آماده ای در نرم افزار spss وجود ندارد.
با سلام. برای یک پایان نامه پرسش نامه ای طراحی شده که اغلب داده های مرتبط با فرضیه به ورت توصیفی تشریحی هستند و تعدادی از آن ها به صورت ترتیبی هستند. برای آزمون فرضیه از چه روشی می توان استقاده نمود؟
سلام؛ با این اطلاعات کم نمی توان در خصوص روش آماری اظهار نظر کرد. بستگی به فرضیات دارد.
اگر مایلید ما تحلیل آماری شما را به انجام برسانیم، پرسشنامه و پروپوزال و فرضیات را در واتس آپ یا ایمیل برای ما ارسال نمایید تا قیمت و زمان انجام کار را اعلام کنیم.
سلام
پایان نامه من بررسی رابطه هست
4 تا شاخص برای بررسی متغیر وابسته و سه شاخص برای بررسی متغیر مستقل دارم
4 تا هم مدل دارم
ایا برای بررسی رابطه بین اینها می تونم از رگرسیون چند متغیره استفاده کنم؟
سلام؛ احتمالا شما لازم است برای برآورد مدلها و تایید آنها از مدل سازی معادلات ساختاری با لیزرل یا اسمارت پی ال اس استفاده نمایید.
سایت lisrel.ir را ببینید.
اگر مایل باشید ما آمادگی داریم تحلیل معادلات ساختاری را انجام دهیم. به ما ایمیل با واتس آپ بزنید.
با سلام و خسته نباشید
چگونه می توان داده های پرت را شناسایی و میزان آن را گزارش کرد. (رهخی غیر از نمودار پراکنش وجود دارد؟)
اگر همبستگی بین دو متغییر معکوس باشد آیا ضرایب رگرسیونی مربوطه نیز منفی می شوند؟
سلام. نمودار سری زمانی داده ها را که رسم کنین معلوم می شود که کدام یک از داده های یک متغیر پرت افتاده اند. با اکسل رسم کنین. نمونه باکس پلات در spss هم برای تشخیص داده های پرت خوب است.
بله اگر همبستگی متغیر وابسته با مستقل معکوس باشد، آن متغیر مستقل در معادله رگرسیون برآورد شده ضریب منفی خواهد داشت و برعکس.
سلام.خسته نباشید ببخشید یه سوال داشتم .مقادیر T که در جدول رگرسیون چند متغیری به روش همزمان وجود داره رو باید با چی مقایسه کرد که متوجه رد فرض صفر یا قبول اون بشیم. البته ستون کنارش P هست ولی من میخوام از طریق T متوجه بشم نتیجه چی میشه وو اینکه یه سال دیگه اینکه قاعدتا این T با آزمون T student که برای مقایسه میانگینها هست فرق داره؟ یه سوال دیگه اینکه مقدار F در جدول تحلیل واریانس جهت ازمون معناداری مدل ارائه شده چجوری تحلیل میشه؟ با چی مقایسه میشه؟ وو چی ازش متوجه می شیم ممنون
سلام. 1- برای متوجه شدن قبول یا رد فرض صفر لازم است عدد p را با عدد 0.05 مقایسه کنید. این روش معمول و صحیح است. از روز آماره t هم می شود اما اصولا نرم افزار p (پی ولیو) را گزارش می کند که کار ما را راحت کند. اگر خواستید باید عدد t را با جدول آزمون t که در انتهای کتابهای آماری هست مقایسه کنید تا معنی داری را نتیجه بگیرید.
2- بله این t جریانش و تحلیلش با t مقایسه میانگین ها فرق دارد. ولی خوب هر دو آزمون تی استیودنت هستند.
3- برای معنی داری مدل رگرسیون، مقدار احتمال آماره F را با 0.05 مقایسه کنین. اگر اون احتمال کمتر از 0.05 بود، مدل معنی دار است.
این صفحه سایت دیگر ما را نیز مطالعه کنید: آزمون معنی داری رگرسیون و ضرایب آن با نرم افزار SPSS
با سلام خدمت مدیریت سایت
در ارتباط با فرضیاتی که تأثیر گذاری را می سنجد می توان از ابتدا از آزمون رگرسیون استفاده کرد؟
سلام. بله. دقیقا وقتی صحبت از تاثیر معنی داری یک متغیر بر متغیر دیگر است، رگرسیون یکی از روشهای بسیار پرکاربرد آماری است.
سلام.ممنون از توضیحاتتون. تقریبا متوجه شدم. من کار آماریمو داده بودم برام انجام بدن الان داشتم میخوندمش. در یه جای نوشته (( همان طورکه درجدول فوق ملاحظه می شود برای ازمون معنی داری ضرایب بتای محاسبه شده ازمون اماریT استفاده شده است . نتایج نشان می دهد که راهبردهای پذیرش،ارزیابی مجدد مثبت و کم اهمیت شماری بطور مثبت ومعناداری بهزیستی روانشناختی را تبیین می کند.)) الان داخل این جمله نوشته برای معناداری آزمون T استفاده شده. براین اساس سوالمو پرسیدم که ببینم این تی همون تی معروفه یا نه جزیی همون جدوله.شما فرمودید متفاوته ولی باز تی استیودنت هست.خواستم بدونم ینی همون آزمون T?? من فکر میکنم اون آزمون تی نیست. گفتم شایدد این یارو که برام تحلیل ها رو انجام داده اشتباه لفظی اینجوری نوشته((آزمون آماری T)). و دوم اینکه شما داخل همون صفحه ی سایت نوشتید (( مقدار آماره ی آزمون معنی داری مدل که همان آماره F است برابر ۴٫۴۲۰ است که با مقدار حاصل از جدول توزیع فیشر با p-1=3-1=2 و n-p=50-3=47 درجه ی آزادی مقایسه می شود (عدد ۵۰ تعداد کل مشاهدات است)) الان اینجا شما گفتید مقدارF رو با توزیع فیشر مقایسه می کنید .الان اینجا شما فرمودید با 0/05 ینی مثل همون پی؟ نظرتون چیه؟ ینی F هم با همون سطح 5 صدم مقایسه می کنیم؟ بازم ممنون ازتون. خیلی بهم کمک کردید. ممنونم…
سلام. هر دو راه درست است. چه بر اساس آماره تصمیم گیری شود و چه بر اساس مقدار احتمال آن (و مقایسه با 0.05).
این t اون t معروف نیست و اینجا وضعیت کمی تفاوت می کند. درسته
متاسفانه مشاورای آماری ای هستند که بعد از ارائه تحلیل، پشتیبانی نمیدن و حتی سوالات را هم حاضر نیستن جواب بدن. پولو که گرفتند دیگه شما را نمی شناسن! اینها اکثرشون رشته آمار نخوندن و گرنه آماری ها اصلا اینطور اخلاق هایی ندارن
حضور جناب آقای فرشچی
باسلام و احترام
در تحلیل مقدماتی مفروضات رگرسیون چندگانه برای تعیین ” ارتباط بین متغیر وابسته و مستقل ” از راه scatter plot ارتباط هر متغیر مستقل را با متغیر وابسته به طور جداگانه بدست آوردم، اما برای تفسیر نمودار بامشکل مواجه شدم چون با هیچکدام ازنمودار هایی که در سایتهای مختلف توضیح داده شده مطابقت ندارد و نمیشود خطی مستقیم در بین نقاط رسم کرد از طرفی منحنی یا خوشه ای هم نیست . صمیمانه پذیرای راهنمایی شما هستم.
سلام. صرف نمودار پراکنش یا اسکتر پلات کفایت نمی کند برای سنجش همبستگی. بلکه آزمون ضریب همبستگی پیرسون یا اسپیرمن (اگر داده ها نرمال نیستند) را بگیرد.
اگر نمی شود خطی یا روندی در نمودار پراکنش دید، این نشان می دهد که همبستگی وجود ندارد.
باسلام و احترام
از لطف شما سپاسگزارم
متغیر مستقل من شامل 5 خرده مقیاس است و متغیر وابسته شامل 2 خرده مقیاس
که فقط دوتا از متغیرهای مستقل و یکی از متغیرهای وابسته نرمال بودند. چون حجم نمونه 476 تا بود، طبق نظر بائو و بکمن از نرمالیتی صرف نظر کردم.
ارتباط متغیرهای مستقل را جداگانه با متغیرهای وابسته از طریق اسپیرمن و پیرسون بدست آوردم که تفاوت چندانی باهم نداشتند. فقط یکی از متغیرهای مستقل با متغیرهای وابسته ارتباط داشت که ضریب همبستگی بالا نبود. الان نمیدانم اصلا میشود از رگرسیون چندمتغیره استاندارد استفاده کرد یا باید راه دیگری انتخاب کنم . درضمن مقدار مجذور R در جدول model summary برابر با 3/2 درصد می باشد که بسیار پایین است و طبق مطالب عنوان شده در سایت شما باید مدل دیگری انتخاب شود، که من از آن اطلاعی ندارم.
سلام. اگر مقدار R2 در مدل رگرسیون برابر 3.2 درصد است، این نشان می دهد که مدل برازش ندارد و مدل مناسبی نیست و فرضیات شما تایید نمی شود.
اگر باقیمانده های مدل رگرسیون نرمال باشند و همخطی بین متغیرهای مستقل مدل نباشد، در استفاده از رگرسیون مشکلی وجود ندارد.
باسلام و احترام
سپاسگزارم
آیا منظور شما از هم خطی بین متغیرهای مستقل همان عدم چندخطی بودن است ؟ این را از طریق VIF(کمتر از 10 بود) و Tolarence(بیشتر از 0/1 بود) بررسی کردم . و همچنین از طریق جدول correlation
که ارتباط متغیرهای مستقل کمتر از 0/74 بود. آیا این برای نتیجه گیری در مورد عدم چند خطی بودن کافی است؟
سلام. بله ، همخطی را VIF می توان بررسی نمود.
جدول همبستگی هم راه خوبیه. اگر میزان همبستگی 74 درصد است که بالاست و نشان دهنده هم خطی است و باید یکی از اون متغیرهای مستقل حذف شود
سوال دوم این است که
آیا راهی برای پیدا کردن ارتباط 5 متغیر مستقل و دو متغیر وابسته براساس تفکیک جنسیت بطورهمزمان هست ؟
چون اگر بخواهم برای هر کدام از متغیرهای وابسته یک بار به تفکیک جنسیت رگرسیون بگیرم بخش نتیجه خیلی طولانی می شود.
باتشکر
احتمالا از مدل سازی معادلات ساختاری باید استفاده کنید. سایت lisrel.ir را ببینید.
باسپاس
امکان دارد بفرمایید ضریب همبستگی چقدرباشد قابل قبول است.
و از مفروضه چندخطی بودن تخطی محسوب نمی شود.
مقدار مشخصی ذکر نشده است، اما همبستگی بیشتر از 0.7 خیلی بالاست و نمی تواند نشانه عدم هم خطی باشد.
برای تشخیص قطعی از آزمون VIF استفاده کنید.
باسلام و احترام
از لطف شما سپاسگزارم
جناب آقای فرشچی
درود و سلام.
ببخشید چطور میتوان خطی بودن متغیرهای مستقل و وابسته را مشخص کرد.
تشکر
سلام و روز بخیر. منظورتان خطی بودن مدل رگرسیون است؟ یا بررسی هم خطی متغیرهای مستقل مدل که یکی از پیش فرض های رگرسیون است؟
هم خطی فقط برای متغیرهای مستقل مدل انجام می شود بدین معنی که متغیرهای سمت راست معادله رگرسیون نبایستی خود با یکدیگر همبستگی بالایی داشته باشند.
برای بررسی هم خطی می توانید از ماتریس همبستگی دو به دوی متغیرها و بررسی آن استفاده کنید (در این ماتریس نباید همبستگی دو متغیر مستقل خیلی بالا باشد و گرنه یکی از آنها را باید از مدل حذف کنید) یا استفاده از آزمون VIF (برای بررسی دقیق تر).
درود و سلام جناب فرشچی
بله مد نظرم پیش فرض خطی بودن هم در MANOVA و هم در Regrresion است ، دوتا مفروضه نوشته شده ، خطی بودن ( وجود رابطه خطی مستقیم بین جفت متغیرهای وابسته ) و چند هم خطی و تکینی
برای فرض عدم چند خطی بودن بررسی ارتباط متغیرهای پیش بین باهم معمولا بین 0.3 تا 0.7 است ، ولی مقدار VIF زیر 3 می باشد. آیا فرض خطی بودن برقراراست ؟
اگر ارتباط پایه تحصیلی (در 3 سطح ) را با تمایل به برقراری ارتباط به زبان انگلیسی (از دو طریق) مد نظر باشد. استفاده از MANOVA صحیح می باشد؟
اینجا کدام متغیرها نباید باهم همبستگی بالایی داشته باشند؟ من برای برقراری ارتباط همبستگی گرفتم که هر دو باهم 0.721 بود ولی VIF پایین تر از 2 بود.
باتشکر
سلام. VIF کمتر از 3 اوکی است و مشکل هم خطی وجود ندارد.
توجه شود که همبستگی با VIF فرق دارد و این دو مثل هم نیستند. بنابراین بهتر است هر دو نتیجه نشان دهنده عدم هم خطی باشند.
آیا میشود خطی بودن را با استفاده از مسیر graph – legacy dialogs- scatter plot- matrix scatter مشخص کرد؟
سوال دیگر در مسیر descriptive statistics- explor در بخش dependent متغیر وابسته وارد میشود در قسمت lable cases by هرکدام از متغیرهای وابسته را به دلخواه میتوان وارد کرد یا فقط باید متغیر ID وارد شود.آیا برای بررسی هریک ازمتغیرهای مستقل چند سطحی با متغیر وابسته باید مفروضات جداگانه بررسی شود یا چون متغیر وابسته ثابت است یک بار گزارش شود کافی است؟
وقتی ماتریس همبستگی ها می گیرید و VIF ، دیگر اسکتر پلات خیلی کارایی ندارد. مگر برای بررسی خودتان
درود وسلام جنای آقای فرشچی
ممنون از پاسخ های شما
فقط جواب سوال آخر را دریافت نکردم
اینکه چند متغیر مستقل چند سطحی دارم ( پایه تحصیلی ، رشته تحصیلی ….. ) و دو متغیر وابسته ، اگر گل مفروضات که پیش نیاز MANOVA می باشد برای پایه تحصیلی انجام شده و گزارش شود. مجدد باید برای رشته تحصیلی هم انجام شده و گزارش شود؟ یا یک بار انجام شود کافی است.
سلام
وقت بخیر
من پایانامه م رابطه بین متغیرها است از روش رگرسیون چند متغیر استفاده کرده ام الان فقط ماتریس همبستگی متغیرهای پژوهش م مونده نمی دونم چه جوری بنویسم همونی
که متغیرها و سطح معنی داری را در جدول می نویسن؟
ممنون میشم کمکم کنید
سلام. نه. ماتریس همبستگی بین متغیرها با جدول برآورد مدل و ضرایب رگرسیون متفاوت است. دستور محاسبه همبستگی دو به دو متغیرها را اجرا کنید. خروجی نرم افزار به صورت یک ماتریس است.
با سلام پایان نامه من روی موضوع تاثیر خشکسالی یا بارندگی در ابعاد اقتصادی، اجتماعی و زیست محیطی زندگی مردم روستایی است. خشکسالی یا میزان بارندگی بعنوان متغیر مستقل است و میتوانم هم در دو بعد(کاهشی یا افزایشی ) در نظر بگیریم و هم بصورت میلیمتر بارندگی. اما زندگیمردم با ابعاد سه گانه اقتصادی ، اجتماعی وزیست محیطی بصورت طیف پنج قسمتی لیکرت و بصورت رتبه ای (1تا 5) سنجیده شده و اینها متغیر وابسته هستند. هرکدام از این سه بعد با تعدادی مولفه در قالب همین طیف رتبه ای بررسی شده. لطفا برای بررسی رابطه بین متغیر مستقل و وابسته و روش آماری مناسب مرا راهنمایی کنید
سلام. چون میزان بارندگی عدد واقعی است و دارای بازه زمانی است، نمی شود با ابعاد اقتصادی و فرهنگی و … که نفرات توسط پرسشنامه تکمیل می کنند همبستگی گرفت چون حجم نمونه متفاوتی دارند.
بهتر است که پرسشنانه رو طوری طراحی کنید که سوالات پرسشنامه تاثیر متغیر مستقل و وابسته را روی هم بسنجد و بعد از تی تست و رتبه بندی فریدمن و تحلیل عاملی تاییدی مرتبه دوم استفاده کنید.
در صورت نیاز با ما ارتباط تا به صورت مشاوره یا انجام تحلیل خدمت شما باشیم.
با عرض سلام و احترام اگر در مینی تب متغییر e داشته باشیم ولی در آزماشگاه دو داده برای آن بدست بیاوریم باید در مینی تب چگونه آن را وارد کنیم ضمن اینکه بعد از وارد کردن داده ها مینی تب Error میدهد مثلا یک بار e شده 65 و بار دیگر e شده 68؟؟
سلام. متوجه سوال شما نشدم، اما یک کتاب خوب در زمینه آموزش مینی تب داریم با قیمت بسیار مناسب. در منو محصولات کتاب “آمار کاربردی با مینی تب” را دریافت نمایید. از روی این کتاب خیلی راحت می توانید با این نرم افزار آماری کار کنید.
سلام خداقوت ممنون اط مطالب خوبتون د مورد آزمون سوبل هم اطلاعاتی دارید ؟
سلام. آزمون سوبل برای بررسی متغیر میانجی و تاثیر غیر مستقیم استفاده می شود.
می توانید به منابع نرم افزار اسمارت پی ال اس مراجعه نمایید . و نیز سایت این مجموعه به آدرس: http://www.smartpls.ir
سلام
خسته نباشید
من یه پرسشنامه دارم که کاملا طیف لیکرته با چندتا سوال مربوط به سن و درامد و این چیزا.
حال میخوام نرمال بودن داده هام رو بررسی کنم.
آیا طیف لیکرت اصلا میتونه نرمال باشه؟
اگه امکان بررسی داره لطفا بهم بگید با چه نرم افزاری امکانش هست؟
سلام. داده های طیف لیکرت اعدادی شامل 1 تا 5 هستند و قاعدتا این اعداد نمی توانند نرمال باشند.
اما توجه داشته باشید که در محاسبه متغیرها، معمولا چند سوال پرسشنامه اشاره به یک عامل (متغیر) دارند. این عامل با میانگین گیری از پاسخ های طیف لیکرت اون سوالات بدست می آید. این متغیر که میانگین گیری شده است یک عدد نسبی است و می تواند نرمال باشد و نرمالیتی آن آزمون شود.
در منو محصولات این سایت “آزمون کلموگروف اسمیرنوف” را انتخاب تا آموزش تست نرمالیتی در spss را دریافت دارید.
سلام
با چه نرم افزاری می توانم در مدل رگرسیون لجستیک، نمودار تغییرات نسبت احتمال رخداد متغیر وابسته به عدم رخداد آن را بر حسب یک متغیر مستقل فاصله ای رسم کنم؟
در واقع به دنبال الگوی رفتار متغیر وابسته نسبت به متغیر مستقلی هستم که در مدل معنادار است.
سلام. تا بحال چنین نموداری ترسیم نکرده و نمی دانم. سایر دوستان اعلام نظر کنند
سلام
ممنون از مطالب مفیدتون
من 4 تا متغیر دارم که یکی از این چهارتا دو بعد داره
هر چهار متغیر رو با مقیاس های ترتیبی سنجیدم و طیف همه ی متغیرهام 5 گزینه ای لیکرت هست
هر متغیر هم دارای سه سوال هستند(البته متغیر دو بعدیم دارای 6 سوال است و هر بعد سه سوال) و پاسخ ها از کاملا مخالفم تا کاملا موافقم می باشند و کلیه ی 400 پاسخ رو هم وارد نرم افزار کردم
حال سوال اولم این هست که: برای ساختن متغیرها از سوالات مربوطه شون باید چه عملی انجام بدم؟( در compute من اونها رو با هم جمع بزنم، میانگین بگیرم، میانه بگیرم، مد بگیرم … چکار بکنم؟
و سوال دوم اینکه: برای متغیری که دو بعد داره، هم خود متغیر کلی را باید در تحلیل ها به کار ببرم و هم هر یک از بعد ها را به صورت جداگانه، حال برای ساختن ابعاد باید به هر بعد سه سوال مربوط به خودش رو بدم و به متغیر کلی هر 6 سوال رو؟
ممنون میشم اگر راهنمایی بفرمایید
سلام. خواهش. برای ساختن متغیرهایتان از اکسل استفاده کنید و متغیرهای ساخته شده را به spss منتقل کنید. کار در اکسل راحت تر است.
متغیرهایی که گزینه های آنها مثل هم است را می توانید جمع بزنید یا میانگین بگیرید که میانگین بهتر است، تا به متغیر جدید (عامل) برسید.
متغیری که دو بعد دارد، در تنظیمات و خروجی های نرم افزار می توانید به گونه ای خروجی بگیرید که به ازای هر بعد خروجی بدهد نرم افزار.
سلام خسته نباشید
آیا امکان چک کردن یک تحلیل آماری رو دارید؟ومبلع رو هم بفرمایید .ممنونم
سلام. بله با همکارمان در واتس آپ ارتباط بگیرید. می توانیم بگوییم که تحلیل آماری به درستی انجام شده یا خیر. هزینه این بررسی در حد هزینه بسته مشاوره تلفنی است که در منو محصولات سایت قابل خریداری است.
البته اگر می خواهید با کار بر روی داده ها و خروجی گرفتن از نرم افزار، چک کردن خروجی ها نیز انجام شود، هزینه اش فرق دارد و بعد از بررسی همکارمان به شما قیمت و زمان اعلام خواهند نمود.
با سلام و وقت بخیر، سپاس فراوان برای مطالب و پاسخ های آموزنده ،
در پژوهشی که 5 متغیر مستقل و 3 متغیر وابسته دارد در هر گروه و بدنبال پیدا کردن نقش و تاثیر متغیر مستقل بر متغیرهای وابسته می باشد.. از تحلیل رگرسیون چند متغیره برای تبیین استفاده کردم سطح سنجش متغیر های مستقل ترتیبی و در طیف لیکرت می باشد و هر متغیر صرفا با یک گویه سنجیده شده است متغیرهای وابسته هر کدام با چندین سوال در طیف لیکرت سنجیده شده اند.. با استفاده از دستور کامپیوت متغیرهای وابسته از جمع زدن گویه های مرتبط آنها ساخته شد و بدین ترتیب سطح سنجش متغیرهای وابسته فاصله ای شده است… آزمون نرمال بودن داده ها برای متغیرهای مستقل و وابسته انجام شد که تمامی وابسته ها نرمال بودند اما متغیرهای مستقل در گروه اول که حجم نمونه 400 پرسشنامه بوده نرمال نبودند اما در دو گروه دیگر با حجم کمتر از 20 نرمال بودند..
ماتریس پراکنش متغیرهای مستقل و وابسته هم رسم شد که رابطه هم خطی و استقلال متغیرهای مستقل را نشان می داد..
سوالات: 1- برای سنجش همبستگی متغیر مستقل و وابسته بدلیل نرمال نبودن و ترتیبی بودن متغیر مستقل ( هرچند وابسته فاصله ای بود) از اسپیرمن استفاده شد.. آیا درست است؟
2- برای سنجش مدل تبیینی از تحلیل رگرسیون چند متغیره استفاده شد که توزیع باقیمانده ها نرمال بود …آیا اینکه متغیر مستقل ترتیبی بود و برایش رگرسیون گرفته ایم اشتباه کردیم؟ بعبارت دیگر برای استفاده رگرسیون خطی حتما باید سطح سنجش متغیر مستقل هم فاصله ای باشد( و فاصله ای بودن متغیر فاصله ای کفایت نمی کند؟ ) ؟
سلام. با توجه به اینکه چند متغیر وابسته دارید، به مبحث مدل سازی معادلات ساختاری نیز نگاهی داشته باشید. احتمالا از این روش باید استفاده کنید.
سوال1: درست است.
سوال2: نرمال بودن باقیمانده ها اصل و ملاک کار است نه نرمال بودن متغیرها. در کل این مدل رگرسیونی که گرفتید چندان دلچسب نیست. بهتر بود متغیرهای مستقل شما نیز از وضعیت طیف لیکرت خارج می شدند (هر متغیر با چند سنجش می شد). با استاد مشورت داشته باشید.
با سلام و خسته نباشید
ممنون می شم در رابطه با سوالات زیر روشنگری کنید..
1- برای استفاده از رگرسیون چند متغیره حتما باید سطح سنجش مستقل و وابسته فاصله ای نسبی باشد یا صرفا فاصله ای بودن متغیر وابسته کفایت می کند؟
2- در شرایطی که متغیر مستقل صرفا با یک سوال در طیف لیکرت سنجیده شده و نمی شود با کانمپیوت تبدیل به فاصله ای کرد آیا راه حل دیگر برای تغییر سطح سنجش ترتیبی به فاصله ای این متغیر وجود دارد؟
پیشاپیش سپاسگزارم
سلام. 1- قطعی نمی توانم اعلام نظر کنم. بهتر است متغیر مستقل از نوع طیف لیکرت نباشد. مگر این که چندین متغیر مستقل با مقیاس نسبی داشته باشید و خوب یکی شون مقیاس ترتیبی باشه. نه اینکه همه شون ترتیبی باشند.
2- راهی وجود ندارد.
با سلام
در مطالعاتی که در مورد رگرسیون داشتم به این نتیجه رسیدم که در استفاده در رگرسیون خطی در صورتی که متغیر مستقل ترتیبی و متغیر وابسته فاصله ای -نسبی باشد و توزیع باقیمانده در رگرسیون نرمال باشد شرط کمی بودن متغیر وابسته و مستقل قابل اغماض هست و می توان از رگرسیون بهره برد… آیا این نتیجه درست است؟
برای سنجش تاثیر متغیر مستقل بر وابسته و استفاده از رگرسیون کدام مفروضات استفاده از رگرسیون اهمیت بیشتری دارد و باید حتما بررسی شود ؟
-نرمال بودن توزیع داده ها که ضروری نمی باشد ( برای اینکه در اصل نرمالی توزیع باقیمانده اهمیت دارد…).
– برقراری شرط استقلال متغیرهای مستقل از هم چقدر مهم است و آیا باید بررسی شود؟
– فرض کمی بودن دو متغیر مستقل و وابسته چطور؟ کمی بودن متغیر وابسته کفایت می کند؟
– رابطه خطی داشتن با چه شیوه ای بررسی می شود؟ ماتریس پراکنش دادهها کفایت می کند یا باید از اسپیرمن یا پیرسون استفاده کرد قبل از استفاده از رگرسیون؟
– آیا خود رگرسیون برای سنجش همبستگی و درجه تاثیر و معناداری کفایت می کند و نیازی به سنجش همبستگی متغیرها قبل از انجام رگرسیون وجود ندارد؟
با سپاس فراوان
سلام. تا حدی قابل اغماض است.
بررسی مفروضات پایه رگرسیون بستگی به دقت تحلیلها تفاوت دارد. برخی اساتید خیلی سخت گیرانه برخورد می کنند و برخی خیر. نرمال بودن باقیمانده ها و استقلال متغیرهای مستقل مهم هستند.
سنجش همبستگی متغیرهای مستقل برای بررسی عدم همخطی متغیرهای مستقل (یا همان استقلال متغیرهای مستقل) استفاده می شود و کاربرد دیگری ندارد.
با سلام
یه سوال دیگه هم داشتم، در شرایطی که حجم نمونه 14 یا صرفا 4 نفر می باشد آیا استفاده از رگرسیون گمراه کننده نخواهد بود در نمونه 4 نفر غالب همبستگی با پیرسون معنادار نبودند و برخی همبستگی کامل را نشان داده و وقتی رگرسیون خطی می گیریم آمار تاثیر و نمودارها کامل نمی شوند … این به چه معناست؟ و چه تفسیری دارد؟
مقدار و سطح معناداری آزمون های t و f با نقطه مشخص شده است این به چه معناست؟
سلام. با 14 تا داده نمی شود رگرسیون گرفت. فکر نکنم باقیمانده ها نرمال شود. با 4 تا نمونه که قطعا رگرسیون معنایی ندارد و نرم افزار خروجی نمی دهد.
سپاس فراوان برای پاسخ های عالی و روشنگری و راهنمایی های ارزشمندتان،
با سلام خدمت شما ببخشید بنده در رگرسیون لجستیک یه مشکل دارم مدل در جدول omnibust در حالت کلی معنی دار است و هاسمر لمشو هم که نیکویی برازش مدل است بالای 0.9 است بنابراین در حالت کلی مدل تایید می شود. ولی بعضی از متغیرها معنی دار نیست و در بعضی مواقع همه شون معنی دار نمی شوند البته من نمی خواهم بررسی معنی داری متغیر ها رو انجام دهم من بیشتر با اون جدول طبقه بندیش که دو حالت قرار می دهد کار دارم می خواستم بدونم این معنی دار نبودن توی اون تاثیر میذاره؟
سلام. سوالاتی در این سطح از فنی بودن را نمی توان در دیدگاه پاسخ داد. لطفا در واتس آپ با همکار ما ارتباط بگیرید. اگر بخوبی متوجه سوال شما بشوند به شما خواهند گفت محصول مشاوره تلفنی را خریداری نمایید.
با سلام. سوال داشتم ممنون میشم راهنمایی بفرمایید. آیا وقتی که از پرسشنامه تحلیل سلسله مراتبی استفاده میکنیم ونرم افزارشم اکسپرت چویس هست امار توصیفی و استنباطی داریم؟ اصلا چجوری تعریف میشوند؟
آیا زمانی که کل جامعه آماری مطالعه میشود آمار استباطی موضوعیت دارد؟
سلام. پرسشنامه های تحلیل سلسله مراتبی یا ahp کلا با پرسشنامه های رایج spss تفاوت دارند. وقتی این پرسشنامه های ahp را وارد نرم افزار اکسپرت چویس می کنیم، خروجی نرم افزار رتبه بندی معیارها و گزینه هاست و از ازمون های آماری خروجی نمی دهد. سایت مخصوص ما در خصوص نرم افزار اکسپرت چویس را حتما ببینید، محصولات آموزشی (ویدئویی) بسیار خوبی دارد : https://www.expertchoice.ir/
– وقتی کل جامعه آماری را بررسی می کنیم دیگر استنباط آماری و آزمون آماری معنایی ندارد، می شود سرشماری. استنباط آماری هدفش این است که با دریافت اطلاعات از نمونه ای کوچک در خصوص کل جامعه آماری اعلام نظر کنیم.
سلام وقت بخیر
سوالی داشتم در مورد نرم افزار PLS، آیا راهی هست که مدل مفهومی رو با تمام مولفه ها و سوالات پرسشنامه یکجا در شکل داشته باشم و بتونم ازش عکس بگیرم؟ مدل من برای هر متغیرش حداقل 15 تا سوال داره و وقتی همه متغیرها رو از حالت hide خارج میکنم یک شکل بهم ریخته و نامشخص بهم میده.
و یک سوال دیگه، اونم اینکه آیا در گزارشات مدل اندازه گیری، آماره F , Q باید گزارش شود؟ و آماره های Ave ، communality, CR, آلفای کرونباخ، ماتریس در روش فورنل و لارکر (1981) کافیه؟ ممنون
سلام. در قسمت منوی نرم افزار سایز مدل را کوچک کنید.اگر تعداد سوالات خیلی زیاد باشد مدل به هم ریخته خواهد شد.
برای سوال دوم :
بله همه موارد لازم هست که در تحلیل بیایند.
درود برشما با داشتن ماتریس Rxy یعنی r1yوr2yو r3y ضریب همبستگی کل چگونه بدست میاید
سلام. این ها سوالات سختی و با توابع جبری است و در اینجا نمی توانیم پاسخ دهیم.
سلام وقت شما بخیر. یک سوال خیلی مهم دارم که ممنون میشم راهنمایی کنید.
برای مطالعات میانجی حداکثر نمونه چند تا باید باشه؟ من برای پایان نامه ام حداکثر میتونم 35 تا بیمار و 35تا کنترل داشته باشم. و بعد در یک مطالعه ی میانجی که یک متغیر مستقل و یک وابسته و یک متغیر میانیجی داره رابطه ی بین متغیرها رو بررسی می کنم . برای چنین طرحی همین اندازه نمونه کافیه؟ من تو پایان نامه های خارجی میبینم خیلی راحت با همین مقدار نمونه از روش بوت استراپ غیرپارامتریک (که البته من خیلی نمیدونم چیه و تو اون پایان نامه ها دیدم) استفاده کردن و نقش میانجی رو بررسی کردن. حتی نقش میانجی های مختلف بین متغیر مستقل و وابسته (که ثابت هستن) به طورجداگانه تو تحلیل های میانجی مختلف بررسی کردن. یعنی مثلا 3 تا متغیر میانجی داشتن و هر کدوم رو جداگانه با یک تحیلیل متفاوت انجام دادن. اما استاد راهنمای من معتقده برای چنین طرحی باید بیش از صد تا نمونه داشت. در حالی که پیدا کردن این تعداد بیمار کم کم دو سه سالی زمان میخاد و من زمانش رو ندارم. و تو پایان نامه های خارجی هم این روش رو به کار گرفتن میشه راهنماییم کنید؟ پاسخ شما برای من بسیار مهم خواهد بود
سلام. حجم نمونه برای بررسی متغیر میانجی حداقل باید ۱۰ برابر بزرگترین متغیر باشد. (یعنی تعداد سوالات متغیری که بیشترین سوال را دارد ضرب در ۱۰).
با سلام وارادت
من می خواهم تاثیر سرمایه فکری با سه عامل(انسانی ُساختاری ُو رابطه ای ) بر توان رقابتی را اندازه گیری کنم
ابزار \رسشنامه
لطفا بفرمایید از چه تحلیل آماری استفاده کنم
۰
سلام. از همبستگی و رگرسیون در نرم افزار اس پی اس اس.
معادلات ساختاری با نرم افزار لیزرل یا اسمارت پی ال اس.
سلام آقای مهندس وقتتان بخیر. آیا بعد از نرمال کردن داده ها توسط sqrt یا log 10 نیاز است که دوباره امتحان کنیم که داده ها نرمال شده اند؟ چون بعد از انجام مراحل باز نرمال نیستند.
آیا آنالیز واریانس آنوا را میتوان روی داده های رتبه ای و غیرنرمال انجام داد؟ از یاریتان سپاسگذارم.
سلام. بله بعد از تبدیل زدن بر روی داده ها هم لازم مجدد نرمالیتی تست شود.
اگر نرمال نیستند داده ها از آزمون های ناپارامتریک استفاده کنید.
سلام و شب بخیر سوالی خدمتتان داشتم اگر تعداد متغیر مستقل ما دو تا باشد ( خودکارآمدی بصورت کمی و سطح سنی بصورت کیفی) و متغیر وابسته کمی باشد و توزیع ما نرمال باشد چگونه رگرسیون میگیریم با تشکر تدریسی
سلام. به همین ترتیبی که متغیرهای مستقل و متغیر وابسته را گفتید در نرم افزار spss با استفاده از دستور رگرسیون، متغیرها را تعریف کنید. توجه داشته باشید که در نهایت می بایست باقیمانده های رگرسیون دارای توزیع نرمال باشند. سایر شروط رگرسیون را نیز بررسی داشته باشید.
در خصوص رگرسیون این صفحه سایت دیگر ما را نیز می توانید مطالعه کنید: مقالات رگرسیون
سلام اگر پس اجرای یک مدل درمان نتایج در پس آزمون گرایش به مرکز داشته باشد یعنی نمره کم یا زیاد مناسب نیست و نمره متوسط مناسب است یعنی اگر در پیش آزمون نمره فرد کم بوده در پس آزمون مقداری افزایش داشته و متعادل شده و اگر در پیش ازمون نمره فرد زیاد بوده در پس آزمون کمتر شده و گرایش به متوسط پیدا کرده و متعادل شده برای تحلیل در spss از کدام مسیر باید رفت و کدام آزمون را باید اجرا کرد ( با گروه کنترل ) در بقیه متغیر ها کواریانس رو اجرا کردم
سلام. سوال خیلی پیچیده مطرح شده، اینطوری نمیشه کمکی کرد. در صورت تمایل سوال تان را به همراه فرضیات و داده ها و خروجی در واتس آپ یا ایمیل ارسال نمایید و بعد از هماهنگی با همکاران ما از مشاوره تلفنی کمک بگیرید. محصول مشاوره تلفنی را از منو محصولات می شود خریداری کرد.
سلام. میخوام برای رگرسیون لجستیک نمودار بکشم چیکار کنم خود اس پی اس اس این کار رو انجام میده ؟چجوری؟
سلام. چه نموداری؟ تحلیل رگرسیون نمودار خاصی ندارد.
اگر نمودارهای توصیفی و نمودار پراکنش منظورتان است به منو آنالیز، بخش Descriptive و سپس نمودارهای مختلف آن مراجعه نمایید. در اکسل هم می شود.
با سلام و احترام
وقت بخیر. ممنون بابت وقتی که می گذارید.
ببخشید یک سئوال داشتم. برای همبستگی ماتریس کواریانس اگر مقیاس متغیرها اسمی یا ترتیبی باشد از مدلیابی معادلات ساختاری استفاده می کنیم که ضرایب مسیر نشان دهنده میزان علیت بین متغیرهاست.
اگر مقیاس متغیرها فاصله ای یا رتبه ای باشد میزان علیت بین متغیرها چطور محاسبه می شود؟ آیا همان ضرائب رگرسیون چند متغیره مربوط به متغیرها همان ضرائب علیت می باشد؟
با تشکر
فقط یک سئوال می ماند. آیا ضریب علیت حتما باید کوچکتر از یک باشد؟ اگر بزرگتر باشد توجیهش چیست؟
سلام خدمت شما!
سوالات پرسشنامه پنج گزینه ای را چگونه ریگریسیون کنم میشه در مورد همکاری نموده معلومات ارائه کنید؟
سلام بر شما. باید اعداد طیف لیکرت را به اعداد نسبی تبدیل کنید. به این ترتیب که با میانگین گرفتن از چند سوالی که یک شاخص را تشکیل می دهند به یک رشته اعداد می رسید و متغیرها محاسبه می شوند. آنگاه می توانید دستور رگرسیون را اجرا نمایید.
این مرکز آمادگی ارائه خدمات به محصلین سایر کشورها را نیز دارد.
با سلام.بنده کار تحقیقاتیم راجب به ترافیک هستش.یعنی تاثر مقومت لغزندگی و زبری و تصادفات بر شاخص ناهمواری روسازی است.در اینجا من امتیاز دهی و پرسشنامه رو به چه طریقی تهیه کنم؟ممنون میشم اگه راهنایی کنید.
سلام. شما می توانید از روش تحلیل سلسله مراتبی عوامل موثر را رتبه بندی کنید و پرسشنامه را با نظر خبرگان تکمیل و تجزیه و تحلیل نمایید. سایت ویژه ahp این مرکز:
http://www.expertchoice.ir را مطالعه داشته باشید. این یک پیشنهاد است.
با سلام.بنده کار تحقیقاتیم راجب به اثر پارامترهایی همچون لغزش جاده و شرایط جاده و تثادفات بر شاخص ناهمواری زمین هست.یعنی یک متغیر وابسته دارم وچند متغیر مستقل.برای تهیه ی پرسشنامه و امتیاز دهی چگونه باید عمل کنم؟
سلام. اگر می توانید با آزمایش های کنترل شده ای برای هر حالت نتیجه را به صورت عددی حساب کنید می توانید از روش آنالیز واریانس استفاده کنید.
سلام
1) داده های من توزیع غیرنرمال دارم. می خوام از آزمون تحلیل عاملی تأییدی استفاده کنم؟ آیا پیش نیاز استفاده از این آزمون، نرمال بودن داده ها نیست؟
2) برای اجرای تحلیل عاملی تأییدی، نرم افزارهای مختلفی وجود دارد، با توجه به اینکه جامعه من غیرنرمال است، استفاده از کدام نرم افزار مناسب تر است؟
با تشکر از پاسخ دهی شما
سلام. اگر حجم نمونه بالا باشد براي بررسي تحليل تاييدي نيازي به توزيع نرمال نيست.
اگر حجم نمونه پايين باشد و يا تحليل تاييدي مرتبه دوم مد نظر باشد بايد از اسمارت پي ال اس استفاده شود.
سلام من الفام خیلی پاییت اومده چکارکنم
سلام. پایایی پرسشنامه تان مورد تایید نیست و لازم مجدد پرسشنامه تان طراحی شود. پیشنهاد می کنم محصول آموزش آلفای کرونباخ را از منوی محصولات دریافت نمایید.
سلام. یه پرسشنامه سی سواله دارم. 335 نفر نمونه. چرا هر چی داده ها رو در pls وارد میکنم اصن جواب نمیگیرم. در مراحل اول بار عاملی و کرونباخ و … خیلی داغون میده که در واقع نمیشه ادامه داد. چرا؟
سلام. داده هاي شما مشکل دارد و مدل رو به خوبي برازش نمي کند.
با سلام
اگر X1 با X2 همبستگی 80 داشته باشد و X1 با Y نیز همبستگی داشته باشد
آیا می توان نتیجه گرفت که X2 نیز با Y همبستگی دارد
و اگر دارد چقدر می باشد
با تشکر فراوان
سلام. بله می توان نتیجه گرفت که همبستگی دارند. اینکه چقدر همبستگی دارند نیاز به مطالب آکادامیک آماری است که الان حضور ذهن ندارم متاسفانه.
با سلام. برای آنالیز تحقیقی با عنوان«بررسی تأثیر وفاداری و تعهد سازمانی بر برند داخلی» از چه روشی استفاده کنیم.
در واقع ما دو متغیر مستقل و یک متغیر وابسته داریم (و دنبال بررسی تاثیر هستیم).
آیا از رگرسیون خطی همزمان (ENTER) می توان برای تحلیل استفاده کرد؟
از روش مدل معادلات ساختاری و نرم افزار لیزرل چطور؟
ممنون میشم ارشاد فرمایید.
سلام. هم مي توان از رگرسيون خطي همزمان استفاده کرد و هم از معادلات ساختاري.
سلام
من یکسری داده دارم که 30 تا بیشتر نیستن. داده های پرت رو هم جدا کردم. الان یک سوال واسم پیش اومده . اعداد ماتریس همبستگی 3تاشون منفی میشه که مربوط به متغیر تعدیلگر من هستن. میخواستم بدونم باید چه کار کنم ؟ آیا این باعث مشکل میشه تووو تحلیل داده هام یا مدلم ؟ یعنی اشتباه ؟
ممنون میشم سریع جواب بدید.
سلام. داده های شما کمتر از 30 است که این خوب نیست. یعنی که در آمار تعداد داده ها می بایست بیشتر از 30 باشد تا بتوان به خوبی تحلیل آنهم از نوع همبستگی داشت. پس ابتدا سعی در افزایش داده ها داشته باشید.
ولی خوب چون نزدیک به 30 است شاید بتوان با اغماض قبول کرد، شما ابتدا نرمال بودن داده ها را کنترل کنید و بعد اگر نرمال بود از آزمون همبستگی پیرسون و گرنه اسپیرمن استفاده کنید.
وجود همبستگی منفی فی نفسه مشکلی ایجاد نمی کند. این بهرحال صحبتی است که داده ها با شما دارند.
با سلام…اگر یک متغیر نرمال و متغیر دیگر غیرنرمال باشد از کدام همبستگی استفاده می کنیم ؟ تعداد نمونه هم 92 نفر باشد ..ممنونم
سلام. در این حالت از ضریب همبستگی اسپیرمن که مخصوص داده های غیر نرمال است استفاده می شود.
با سلام و تشکر
در تحلیل رگرسیون اگر بین دو متغیر پیش بین رابطه وجود داشته باشد از نظر پیش فرض های رگرسیون مشکلی ایجاد نمیکند؟ به عبارتی می توان هدف فرعی یک پژوهش را برر سی رابطه بین دو متغیر که هر دو در نقش متغیر پیش بین پژوهش هستند را مطرح نمود؟
با تشکر
سلام. متغیرهای پیش بین که اسم دیگر متغیرهای مستقل هستند، می بایست ارتباطی با یکدیگر نداشته باشند. به اصلاح دارای هم خطی نباشند و استقلال داشته باشند.
این عدم هم خطی یکی از پیش فرضهای رگرسیون و شرط صحت آن است.
بنابراین نمی توان یکی از اهداف فرعی را بررسی رابطه بین دو متغیر پیش بین یا مستقل تعیین کرد.
سپاسگزارم از پاسخگویی جامع و فوری تان. پاینده باشید.
با درود و احترام
متغیر وابسته چگونه مقداردهی می شود؟
چهار متغیر مستقل خود را با compute کردن گزینه های سوالات پرسشنامه مقداردهی کردم
اما گويا برای رگرسیون، ستون متغیر وابسته نیز باید مقداردهی شود، چگونه؟
با سپاس
سلام. سوال شما را دقیقا متوجه نشدم. رگرسیون بدون متغیر وابسته (که به صورت پیوسته و کمی باشد) امکان پذیر نیست.
پیشنهاد می کنم هر محاسباتی که بر روی داده ها نیاز دارید در اکسل انجام داده و نهایی که شد به spss منتقل کنید.
سلام من 4 متغیر مستقل دارم و یک متغیر وابسته ، که ابتدا هر کدام از این 4 متغیر مستقل تاثیرشون جداگانه بر روی متغیر وابسته سنجیده میشه و سپس این 4 متغیر مستقل در قالب یک متغیر جدید با هم ترکیب می شوند و به شکل کلی اثرشون بر متغیر وابسته سنجیده میشه
هم چنین من دو متغیر تعدیل گر هم دارم ، لازم به ذکر هست که سوالات با طیف لیکرت سنجیده میشن
سوالم این هست که من می تونم از پی ال اس استفاده کنم و یا باید از رگرسیون چندگانه استفاده کنم ؟ ممنون میشم
سلام. چون متغیر تعدیلگر دارید با حتما از پی ال اس استفاده کنید. وب سایت ویژه اسمارت پی ال اس ما: http://www.smartpls.ir
با سلام و خسته نباشید
در صورتی که یک متغیر وابسته و 11 متغیر مستقل (7کیفی و 4 کمی) داشته باشیم مدل رگرسیونی چطور می شود؟
سلام و وقت بخیر. منظورتان از متغیر کیفی چیست؟ با تجمیع و میانگین گیری از پاسخ های طیف لیکرت سوالات پرسشنامه، متغیر مناسب را بسازید و بعد رگرسیون انجام دهید.
سلام و وقت بخیر
نرم افزار spss برچه اساسی رگرسیون نجام میده؟ پارامترهای تنظیم در اون چی هست و اینکه آیا وقتی داره رگرسیون بین داده ها انجام میده داده ها رو شافل یا به عبارتی بهم میریزه تا مدلی براساس کمترین میزان خطا بدست بیاره؟
ممنون میشم راهنمایی بفرمایید
سلام. سوال خیلی کلی است. شما را به دیدین این فیلم آموزشی دعوت می کنم که برای رگرسیون با نرم افزار EViews تهیه کردم {مفهوم رگرسیون و نحوه ورود مدل رگرسیون به نرم افزار}:
https://www.eviews-iran.ir/product/regression-model/
در ویدئوی فوق مفهوم رگرسیون و همبستگی را به صورت کامل توضیح داده ام.
سلام در صورتی که متغیر تعدیل کننده ای داشته باشیم که با طیف لیکرت اندازه گیری می شود ، از کدام رگرسیون برای بررسی آن استفاده می شود؟ سلسله مراتبی یا گام به گام؟
سلام. وقتی متغیر تعدیلگر دارید می بایست از مدل سازی معادلات ساختاری و نرم افزارهایی مثل لیزرل و smartpls استفاده نمایید و با رگرسیون معمولی نمی شود کار کرد. زیرا چندین معادله رگرسیون هم زمان دارید. سایت ویژه نرم افزار اسمارت پی ال اس ما: http://www.smartpls.ir
با سلام
چرا حذف چولگی و نرمال کردن توزیع برای مدل های خطی کاربرد دارد؟
سلام. به این دلیل که در مدل های رگرسیون خطی پیش فرض و شرط صحت برآورد ها توزیع نرمال داشتن باقیمانده ها است و این مهم با حذف چولگی ها و داده های پرت بدست می آید و کنترل نرمالیتی.
برای نرمالیتی این بسته آموزشی جامع و بسیار خوب را داریم (در سایت دیگر این مرکز تحلیل آماری):
https://spss-iran.ir/product/normal-test/
سلام لطفا بفرمایید اصطلاحات آماری که در جدول های spss وجود دارد را ازکجا و چطور ترجمه کنم
سلام. این اصطلاحات فراتر از ترجمه نیاز دارند و شما در اصل نیاز دارید که خروجی نرم افزار مورد تجزیه و تحلیل قرار گیرد. به کتابها یا ویدئوهای آموزش SPSS می توانید رجوع کنید.
در منو محصولات سایتهای ما برخی آموزش های ویدئویی وجود دارد.
سلام من تا سوال دارم خیلی ممنون می شم راهنماییم کنید. من موضوع پایان نامه ام پیش بینی اضطراب امتحان بر حسب سبک دلبستگی و سبک فرزندپروری هست برای تحلیل باید از روش رگرسیون استفاده کنم؟لازم هست میانگین و انحراف معیار هر پرسشنامه رو جدا جدا پیدا کنم؟خیلی ممنون می شم جوابم بدین
سلام. می تواند روش رگرسیون باشد یا حتی ممکن است از مدلسازی معادلات ساختاری استفاده شود. پس از نگارش فرضیات و اهداف و فصل سوم می توان در خصوص روش آماری اعلام نظر کرد.
اصلا لازم نیست خودتان میانگین و انحراف معیار را جداگانه حساب کنید. بلکه باید داده ها به تفکیک هر نفر و هر سوال وارد نرم افزار شود و نرم افزار آماری این محاسبات و سایر محاسبات را انجام دهد.
همکاران ما در این مجموعه آمادگی انجام تحلیل آماری شما را بعد از تعیین تکلیف پرسشنامه و اهداف و فرضیات و جمع آوری داده را دارند.
سلام وقت بخیر . زمانی که هم یک متغیر مستقل ،یک وابسته و میانجی داریم از چه آزمون هایی باید استفاده کنیم ؟آیا می شود متغیر میانجی را به عنوان متغیر مستقل دوم به حساب آورد؟
سلام. از رگرسیون و همبستگی می توان استفاده کرد.
متغیر میانجی بین مستقل اصلی و وابسته اصلی قرار میگیرد. یک بار رگرسیون بین مستقل اصل و میانجی (وابسته) و یک بار رگرسیون بین وابسته اصلی و میانجی (مستقل)
با عرض سلام من رگرسیون گرفتم همه چیز معنا داره جز constant که معنی دار نیست چرا این اتفاق افتاد می شه کاری کرد؟
من از نرم افزارspss استفاده کردم فقط costant معنی دار نیست می شه کاری کرد?
سلام . معنی دار بودن عرض از مبدا یا جمله ثابت در رگرسیون معمولا مهم نیست و در تایید یا رد فرضیات نیز به کار نمی آید. بهرحال در رگرسیون قرار نیست همه متغیرها و جمله ثابت آن معنی دار باشند.
برقراری فروض پایه ای رگرسیون را از جهت نیکویی برازش کنترل نمایید.
با سلام و وقت بخیر. من در بخش اول تحقیقم با استفاده از روش کیفی (نگاشت مفهومی)، در راستای عنوان تحقیقم مولفه هایی را شناسایی (از طریق مصاحبه و کتابخانه ای) و سپس در چندین مرحله، مولفه ها را دسته بندی نمودم و در نهایت مدل از آن استخراج گردید، حال برای ادامه کار برای تایید مدل از چه روشی باید استفاده کنم. لازم به توضیح است که بر اساس مولفه های شناسایی شده ، پرسشنامه ای را جهت توزیع در جامعه آماری آماده کرده ام. لطفا در خصوص روش و نرم افزار مربوطه راهنمایی بفرمایید
سلام. شما الان مدلی را در اختیار دارید. برای تایید آن می توانید از تحلیل عاملی تاییدی استفاده کنید که با نرم افزارهای مدلسازی معادلات ساختاری مثل لیزرل و اسمارت پی ال اس انجام می شود.
سایت دیگر ما را نیز ببینید: http://www.lisrel.ir
سلام وقتتون بخیر. در نرم افزار spss وقتی بیش از ٩ متغیر داریم برای انجام تحلیل رگرسیون چندمتغیره چطور میشه همه را وارد کرد؟ درمسیر تحلیل ظرفیت ورود ٩ متغیر وجود داره ( یعنی ٩ بار next زده میشود) بیش از ٩ متغیر رو چطور میشه برای تحلیل وارد کرد؟
خیلی فوری بهش احتیاج دارم لطف میکنین پاسخ بدین
سلام. متوجه سوال نشدم. در یک مکان از پنجره باز شده، متغیر وابسته و در مکان دیگر متغیرهای مستقل را در کنار یکدیگر و با هم وارد کنید.
بهتر است طبق آموزش یا یک کتاب به کار با نرم افزار بپردازید.
سلام وقت شما بخیر. من تحلیل آماری با 108 نمونه و متغیر های رتبه ای دارم که طبق نظر استاد تحلیل رگرسیون باید انجام بدم .با 3 متغیر مستقل و یک وابسته .لطف می فرمایید راهنمایی کنید از چه دستور رگرسیونی در spss استفاده کنم ?
سلام. برای رگرسیون از دستور
analyze—> regression —>linear
استفاد کنید
با سلام وقت شما بخیر .
ببخشید اگر دو متغیر داشته باشیم یکی نسبی و دیگری طبقه ای( اسمی ) در spss مراحل را بنویسید برای روش همبستگی
سلام. آموزش ویدئویی نحوه ورود داده ها به SPSS از منو محصولات سایت قابل تهیه می باشد.
استفاده از ویدئوهای آموزشی خیلی مفیده، چون در یک فیلم دقیقا نحوه کار با نرم افزار را می بینید. ضمن اینکه می توانید با واتساپ با مدرس دوره ارتباط برقرار کنید.
باسلام
6تا متغیر مستقل با یک متغیر وابسته و یک میانجی داریم. به فرموده استاد از نرم افزار اسمارت پی ال اس استفاده کردم. تعداد نمونه 50 تاست. در قسمت معناداری فقط یک متغیر عدد نرمال در خروجی می دهد. مشکل از چیست؟ از تعداد نمونه؟ یا سوالات اشتباه؟ یا چیز دیگه
سلام.
هرچه تعداد متغیرهای مستقل زیاد باشد احتمال اینکه معنی داری رد بشود بیشتر است.
احتمالا بین متغیرهای مستقل شما همبستگی بالا وجود دارد.
اول در اس پی اس اس رگرسیون گام به گام بگیرید تا مشکل مشخص شود
با سلام
من چند تا سوال داشتم که هرچی تو اینترنت می گردم و مطالعه میکنم جواب هایی رو که دریافت میکنم یکم با هم در تضاده.
1- چرا در مدل یابی معادلات ساختاری از آزمون t استفاده میکنیم بجای P ؟
2- همبستگی پیرسون در یک مدل نرمال همبستگی 2 به 2 متغییر ها با هم (بدون حضور و اثر متغیر سومی ) را مقایسه میکند درسته؟ و در این صورت در حالت آزمون ضرایب مسیر استاندارد در مدل ساختاری با نرم افزار Lisrel اعداد ضریب مسیر بین دو متغییر به چه معناست؟ آیا این بدان معناست که همبستگی دو متغییر اینبار باوجود تاثییرات متغییر های دیگر محاسبه می شوند؟ و اگر این عدد منفی شود به چه معناست؟
3- ارتباط بین دو متغییر را چه زمانی مردود می شماریم؟ زمانی که ضریب مسیر بین آن دو منفی شود یا زمانی که آزمون t آن از 1.96 کوچکتر شود؟
سلام.
۱- پایه ی معادلات ساختاری رگرسیون هست و برای معنی داری ضرایب استاندارد از تی ولیو استفاده می شود. مقدار p ، مقدار احتمال معنی داری است و مهم مقدار t است.
۲- ضریب در مدل ساختاری همان بتا در رگرسیون هست و با مقدار همبستگی متفاوت است. وقتی ضریب منفی است یعنی رابطه ی بین دو متغیر معکوس است. و رابطه ی معکوس با هم دادند.
۳- رابطه زمانی رد می شود که مقدار t کمتر از ۱.۹۶ باشد.
منفی یا مثبت بودن دلیل رد فرضیه می تواند باشد مثلا فرضیه رابطه ی مثبت را مشخص کرده ولی ضریب استاندارد منفی است.
با سلام و احترام.
ببخشید میشه لطف کنید راهنمایی کنید برای تحلیل اماری پایان نامه ی روانشناسی با موضوع بررسی رابطه بین پایگاه هویت و سلامت روان در نوجوانان روی 50 نمونه، باید از چه ازمون اماری استفاده کنم؟با سپاس
سلام و درود.
اگر متغیرهایی که در نهایت برای این دو عامل از روی سوالات پرسشنامه ساخته می شوند، نرمال باشند، آزمون همبستگی پیرسون و گرنه آزمون همبستگی اسپیرمن.
البته اگر مقطع تحصیلی شما فوق لیسانس است که قطعا نیاز به آزمون های آماری پیچیده تری است و به احتمال زیاد لازم است از مدل سازی معادلات ساختاری با نرم افزار اسمارت پی ال اس استفاده نمایید.
ما برای تحلیل معادلات ساختاری آمادگی داریم. وب سایت تخصصی ما برای SEM یا معادلات ساختاری: http://www.smartpls.ir
سلام ببخشید سوالی داشتم
در رگرسیون خطی چند گانه امکان دارد مقدار ثابت معنی دار نشود و وارد مدل نشود؟
بسیار ممنون از شما
سلام. بله. ممکن است معنی دار شود یا اینکه معنی دار نشود. مشکل خاصی ایجاد نمی کند. اگر معنی دار بود در مدل نهایی بیاورید و گرنه نیاورید.
سلام و وقت بخیر استاد فرشچی
با تشکر از سایت خوبتون که مقالات خوبی در رفع ابهام دانشجویان درگیر پایان نامه داره
من یک سوال مهم ازتون دارم که امیدوارم هرچه سریعتر بهش پاسخ داده بشه تا بتونم فصل 5 پایان نامه ام رو جمع بندی کنیم
من 6 تا فرضیه داشتم در پایان نامه که با توجه آزمون اسپیرمن 5 تاش معناداریش با متغیر وابسته ام تایید شد و متغیر مستقل طبقه اجتماعی معنا داریش با متغیر وابسته تایید نشد
من آزمون رگرسیون گرفتم در آزمون رگرسیون با توجه به sig آزمون معنا داری متغیر مستقل طبقه اجتماعی در مدل رگرسیون تایید شد ولی معنا داری دو متغیر مستقل بازاکار و رغبت با توجه به بیشتر بودن مقادیرش از 0.05 در معادله رگرسیون تایید نشد
حالا در تفسیر این اتفاق موندم چه بنویسم
بنویسم متغیر طبقه اجتماعی با اینکه معناداریش با اسپیرمن تایید نشده ولی در معادله رگرسیون هست؟ کدوم معتبره اسپیر من یا رگرسیون؟
در مورد دوتا متغیر بازارکار و رغبت که معناداریشون با اسپیرمن تایید شده ولی در معادله رگرسیون نیست چی بنویسم؟
سلام. خواهش.
نتایج آزمون رگرسیون از آزمون همبستگی معتبر تر است و قاعدتا بایستی آن ملاک عمل قرار گیرد. زیرا . البته دقت نمایید که فروض پایه رگرسیون از جمله نرمال بودن باقیمانده ها و عدم وجود همخطی و امثال آن، برقرار باشد.
اما در حالت کلی شما قاعدتا بایستی یک مقاله بیس داشته باشید تا طبق آن عمل کنید. هر روشی که مقاله بیس دارد همان روش را نیز شما اجرا نمایید.
سلام وقتتون بخیر
من متغیر وابستم بصورت کمی هستش اما متغیر مستقل بصورت اسمی هستش. میتونم از آزمون رگرسیون استفاده کنم؟
سلام. اگر متغیر یا متغیرهای مستقل دیگری هم داشته باشید که آنها کمی باشند، مشکلی ندارد.
اما اگر فقط همین دو متغیر را دارید، نیازی به آزمون رگرسیون نیست و از آزمون تی و مقایسه میانگین ها استفاده نمایید.
با سلام
آیا تعداد نمونه بر معنی دار شدن و یا نشدن ضریب همبستگی تاثیر دارد؟
اگر تاثیر دارد حداقل تعداد نمونه بر معنی دار شدن چقدر است؟
باتشکر
سلام.
1- بله تاثیر دارد. هر چه حجم نمونه بالاتر باشد، شانس معنی دار بودن ضریب همبستگی بیشتر خواهد شد. در نمونه های خیلی بزرگ مثلا با چند هزار داده، مشاهده می شود که همبستگی در حد 10 درصد نیز معنی دار می شود.
یعنی ضریب همبستگی پایین هست اما معنا دار است.
2- حداقل تعداد نمونه قاعدتا بایستی بیش از 15 تا باشد. عدد مشخصی ذکر در منابع ندیده ام من. توجه کنید که اگر داده ها نرمال باشند از همبستگی پیرسون و گرنه از همبستگی اسپیرمن استفاده شود.
سلام و وقت بخیر
امکان استفاده از یک معادله خط برای مثل y=a+bx+cx2 در نرم افزار مینیتب به جای پاسخ چند پارامتر و محاسبه انالیز رپراسیون هست?
سلام. این معادله خط که شما نوشتید به نوعی همان معادله رگرسیون است که از طریق آنالیز رگرسیون بدست می آید. در اصل در خروجی رگرسیون، همین ضرایب a , b, c برآورد می گردد.
کتاب الکترونیکی خوبی در زمینه کار با مینی تب در منو محصولات سایت داریم: https://www.spss-iran.com/product/minitab/
سلام خدمت استاد گرانقدر
در پژوهش بنده 700 نمونه وجود داشت و با نرم افزار SMARTPLS تحلیل انجام داده ام. هر چه جستحو کردم در هیچ مقاله ای حداکثر حجم نمونه برای PLS مشخص نشده است و فقط حداقل گفته شده است. از طرف دیگر استاد هومن در کتاب شناخت روش علمی گفته اند که تعداد نمونه برای تحلیل عاملی حداقل 500 نمونه باشد. پژوهش بنده 10 متغیر مستقل دارد و داده ها نرمال نیست و به همین دلایل از PLS استفاده کرده ام. می خواستم از حضورتون بپرسم که تحلیل 700 نمونه با SMARTPLS امکانپذیر است و این نرم افزار فقط برای نمونه های کمتر از 200 تایی نیست؟ سوال دوم اینکه متغیر تعدیلگر در SMARTPLS می تواند خودش چهارگویه داشته باشد یا حتما قبلا در SPSS باید داده ها میانگینگیری شود و تبدیل به یک گویه شود و بعد وارد SMARTPLS شود؟
ممنون از حضور جنابعالی
سلام
مساله ای نیست حجم نمونه چقدر باشد. فقط شاخص های روایی و پایایی باید خوب باشد. امکان تعریف متغیر تعدیلگر کمی با 4 گویه هم در این نرم افزار وجود دارد.
سایت تخصصی نرم افزار اسمارت پی ال اس: http://www.smartpls.ir
با سلام و احترام
چگونه میتوان به این سوال که چرا شما در این تحقیق از روش مدلسازی ساختاری تفسیری ism استفاده کرده اید ؟؟؟؟ پاسخ داد.
منظور بنده این است که برای توجیه داوران باید چه نکاتی را ذکر کرد.
موضوع تحقیق:ارائه مدل عوامل بحرانی موفقیت در حوزه صنعت می باشد
سلام و درود
روش مدلسازی ساختاری تفسیری (ISM)، یکی از روشهای طراحی سیستمها به ویژه سیستمهای اقتصادی و اجتماعی است. رویکرد ISM، افراد و گروهها را قادر میسازد که روابط پیچیده بین تعداد زیادی از عناصر را در یک موقعیت پیچیده تصمیمگیری ترسیم کنند و به عنوان ابزاری برای نظم بخشیدن و جهت دادن به پیچیدگی روابط بین متغیرها عمل میکند. در این روش با تحلیل تأثیر یک عنصر بر عناصر دیگر، ترتیب و جهت روابط پیچیده میان عناصر یک سیستم بررسی و بدین وسیله بر پیچیدگی بین عناصر غلبه میشود.
از جمله مزایای روش ISM میتوان به قابل درک بودن آن برای گستره بیشماری از کاربران، یکپارچگی آن در ترکیب نظرات خبرگان و قابلیت کاربرد آن در مطالعه سیستمهای پیچیده و دارای اجزای متنوع اشاره نمود (آذر و همکاران، 1392؛ کهریزی و همکاران، 1393).
به هر حال این روش نسبت به سایر روش ها ناشناخته هست و برای دفاع از این موضوع زحمت بسیار باید کشید.
با سلام،
براي محاسبه ضريب همبستگي ارايه هايي كه كمتر از 30 عدد مي باشند آيا حتما داده ها بايد نرمال باشند ؟ همچنين ميزان خطا را در اينگونه داده ها چگونه حساب كرد؟
سلام. ابتدا نرمال بودن را با روش کلموگروف اسمیرنوف آزمون کنید. اگر نرمال بودند از ضریب همبستگی پیرسون و اگر نرمال نبودند از ضریب همبستگی اسپبرمن در منو آنالیز نرم افزار SPSS استفاده نمایید.
منظورتان از خطا دقیقا چیست؟ : وقتی نرم افزار ضریب همبستگی را گزارش می دهد، معنی داری یا عدم معنی داری این ضریب را نیز اعلام می کند.
با سلام استاد ببخشید یک سوال داشتم
رشته من حسابداری هست داده هام کمی ،مقیاس نسبی. من یک متغیر وابسته دارم سه تا مستقل چندتا کنترلی و یه دونه تعدیل کننده.
دو تا فرضیه دارم یکی تاثیر متغیر مستقل و کنترلی بر وابسته هست. و تو فرضیه دومم علاوه بر اینا متغیر تعدیل کننده هم به کار میاد .
سوالم اینه ایا میتونم برای فرضیه اولم از رگرسیون خطی چندگانه و برای فرضیه دوم از تحلیل استفاده کنم یا برای هر دو باید از تحلیل مسیر استفاده کنم؟
سلام. برای هر دو فرضیه باید از رگرسیون خطی چندگانه استفاده بشه. تحلیل مسیر زمانی استفاده می شود که متغیر میانجی وجود داشته باشد.
سلام وقت بخیر
در مطالعه بنده، ابتدا با در نظر گرفتن ضریب پیرسون، بین داده های A و B وC ارتباط معنادار وجود داشت برای تبیین A بر اساس B و C رگرسیون گام به گام انجام دادم و C از معادله حذف شد. با توجه به اینکه بین B و C ارتباط وجود داره آیا نباید رگرسیون زده می شد و اگر رگرسیون قابل قبوله حالا که c حذف شده آیا کل مطالعه زیر سواله؟
سلام. ابتدا باید رگرسیون چندگانه انجام بشه و نتایج تفسیر بشه, و بعد برای بهبود مدل رگرسیون گام به گام انجام بشه.
و البته رگرسیون گام به گام وقتی استفاده میشه که تعداد متغیرهای مستقل زیاد باشد و برازش مدل پایین.
با سلام
من یک رگرسیون چندگانه گرفتم ۷ متغیر پیش بین دارم ضرایب رگرسیون بین متغیرهای مستقل ۰/۷ و ۰/۶ است همخطی بین انها را بررسی کردم همخطی نداشتند اما جهت ضرایب رگرسیون برخلاف انتظار و برخلاف جهت روابط همبستگی بدست امد لطفا راهنمایی بفرمایید که برای حل این مشکل چه کنم.
با تشکر فراوان
سلام. اگر همبستگی بین متغیرهای وابسته و مستقل مثبت است, باید رابطه ی بین 7 متغیر مستقل را بررسی کنید. احتمالا همبستگی شدید بین متغیرها برقرار است. و در مرحله ی بعد رگرسیون گام به گام بگیرید تا متغیر مشکل ساز مشخص شود.
سلام اگر این مفروضات برقرارنباشند ازچه روش هایی برای جبران میتوان استفاده کرد؟
سلام وقت بخیر ازمون الفا مساوی صفر در رگرسیون اماره آزمونش چیه؟؟؟
ممنون میشم جواب بدید
سلام وقت بخیر
اگر در مطالعه 6 متغیر مستقل باشد که دو نوع آن کیفی و 4 نوع دیگر کمی و داری سری زمانی است. متغیر وابسته هم کمی و دارای سری زمانی است. در این صورت میتوانم از رگرسیون استفاده کنم. آخه همانطور که گفتم داده های 4 متغیر مستقل کمی بصورت سری زمانی است متغیر وتبسته هم بصورت سری زمانی از سال 1390 موجود است و میتونم رگرسیون بگیرم. کدام رگرسیون؟ منظور اینه که متغیر مستقل م کیفی هستن برای گذشته داده ای نیست و از پرسشنامه پرسیده شده است.
سلام. ظاهرا داده های خوبی ندارید. برای رگرسیون بایستی حداقل حدود 30 تا داده داشته باشید، و تمام متغیرها در آن سالها داده هایشان موجود باشد (حالا کمی یا کیفی).
با سلام و احترام
سوال من اینه که آیا میتونیم از رگرسیون برای آزمون مدل استفاده کنم؟
سلام. خیر. اگر برازش مدل مفهومی مد نظر باشد باید از روش معادلات ساختاری استفاده کنید.
با سلام و احترام
ضریب همبستگی برای آزمایش گلخانه ای در هفته اول مثبت به دست آمده ولی معنیدار نشده است.به نظر شما اگر این آزمایش گلخانه ای ادامه داشته باشد،ضریب همبستگی با گذشت زمان (2 ماه) میتواند تغییر کند و معنیدار شود.
سلام. معمولا وقتی تعداد داده ها افزایش می یابد، احتمال اینکه ضریب همبستگی معنی دار شود نیز افزایش می یابد، هر چند میزان همبستگی عدد بالایی نباشد.
خاصیت ضریب همبستگی این است که وقتی تعداد مشاهدات زیاد باشد، حتی برای مقادیر همبستگی پایین، معنی دار می شود.
با سلام
در خروجی جدول مربوط به ضریب مسیر و آماره تی original sample O چی هست و نشان دهنده چیست؟ گاهی مثبت و گاهی منفی هست.
ممنون
سلام. ضریب استاندارد مسیر هست. رابطه منفی بین دو متغیر با علامت منفی و رابطه مثبت بین دو متغیر با علامت مثبت نمایش می یابد.
سپاسگزارم
سلام و و قت بخیر آقایفرشچی،
یک سوالی که نتونستم در موراد اموزشیتون بهش دست پیدا کنم.
اینکه رگرسیون چند متغیره و رگرسیون چند گانه با هم متفاوتند.
چند متغیره یعنی چند متغیر مستقل بر چند متغیر وابسته و
چندگانه یعنی چند متغیر مستقل بر یک متغیر وابسته
در نرم افزار spss هم چندگانه قابل اجرا هست از مسیر analys>Regrssion<Linear
اما چند گانه رو نمیشه اجرا کرد در spss؟؟
از تون راهنمایی خواستم با سپاس
سلام. تا بحال رگرسیونی که در آن چند متغیر وابسته باشد را در spss انجام نداده ام. مبحث پیچیده ای است. کلا وقتی با چند متغیر وابسته روبرو هستیم، مبحث مدلسازی معادلات ساختاری پیش می آید و نرم افزارهای لیزرل و ایموس و اسمارت پی ال اس:
https://www.lisrel.ir/
عرض سلام و وقت بخیر؛
ببخشید میخواستم بپرسم وقتی ما داریم در رگرسیون چندگانه فرضیه هامون رو مورد بررسی قرار میدیم، برای هر فرضیه که متغیر پیش بینِ جداگونه داره، باید داده های پرت رو جدا بررسی کرد؟ یعنی یه بار برای فرضیه اول که متغیر پيش بين اول رو میسنجه جدا، یه بار فرضیه دوم که متغیر پیش بین دوم رو میسنجه جدا و… به همین ترتیب تا آخرین فرضیه؟
و دیگه اینکه وقتی داده (های) پرت رو پیدا کردیم، باید اون فردی رو که داده پرت بهش تعلق داره کلا حذف کرد؟
سلام علیکم. کلا مبحث داده های پرت را برای تمام متغیرهای مستقل و برای متغیر وابسته کنترل کنید بعد آزمون را انجام دهید.
وقتی داده پرت را یافتید یا آنرا اصلاح کنید و یا اینکه فقط همان یک سلول را حذف کنید.
سلام
من میخواهم قند خون بعد از غذا را بر اساس قند خون قبل غذا و کربوهیدرات دریافتی و سن و قد و وزن که همه از نوع عددو فاصله ای نسبی هستند پیش بینی کنم، توزیع داده ها نرمال نیست آیا حتما باید از آزمون اسپیرمن استفاده کنم؟(پیرسون نمیشه؟) و اگر باید از اسپیرمن استفاده کنم با توجه به اینکه توزیع داده ها نرمال نیست میتونم از رگرسیون خطی چندگانه استفاده کنم؟(توزیع باقیمانده ها نرمال است واریانس باقیمانده ها ثابت است و … شرط هایش را چک کردم برقرار است همخطی هم وجود ندارد) یعنی برای داده های ناپارامتریک ( توزیع نرمال نیست) میشه از رگرسیون خطی چندگانه استفاده کرد؟
سلام. اگر متغیر وابسته تان به صورت پیوسته و از نوع مقیاس فاصله ای است و تعداد داده ها نسبتا زیاد است، مثلا بیشتر از 50 مورد، از رگرسیون خطی می توانید استفاده کنید. فقط لازم است کنترل کنید که بعد از اجرای رگرسیون، باقیمانده ها دارای توزیع نرمال باشند. گاهی با بررسی داده های پرت، می توان متغیری که نرمال نیست را به نرمال تبدیل کرد.
سلام
وقتتون بخیر
ببخشید اگر بخوام فراوانی داده های یک پرسش نامه به این صورت بدست بیاد که مشخص باشه چه تعداد از افراد نمره بالا تر در پرسش نامه بدست اوردن و چه تعداد نمره پایین تر..میشه بفرمایید باید چیکار کنم؟
با سلام اگه بعد از رسم مدل تحلیل مسیر ویا SEM مشخص بشه ضریب تعین (R2) متغیر میانجی حدود 0/22 هست آِیا مدل ارزش رسم کردن و گزارش رو داره؟
سلام. بله. اغلب برای متغیر میانجی مقدار ضریب تعیین خیلی بالا نیست. مگر اینکه متغیرهای مستقل که روی آن تاثیر می گذارند زیاد باشد و حجم نمونه هم بالا باشد.
عرض سلام و احترام
بنده در رساله ۴ تا متغیر مستقل و دو تا متغیر وابسته دارم برای بررسی روابطشان به طور جداگانه و تعاملشان با هم و نیز ارائه مدل باید از چه روشهایی استفاده کنم؟
سلام. شما به احتمال قوی بایستی از مدلسازی معادلات ساختاری استفاده کنید. این دو سایت تخصصی ما در این زمینه را حتما ببینید و مقالات آنرا مطالعه داشته باشید:
https://www.lisrel.ir/
https://www.smartpls.ir/
سپاسگزارم
با سلام.
با چه روش های آماری و آزمون ها می توان پی برد که کدام متغیرهای میانجی، و کدام یک تعدیل گر هستند؟
با تشکر
سلام. با آزمون های آماری نمیشود که مشخص کرد که متغیر میانجی یا تعدیلگر کدام است. تعریف متغیرها باید قبل از انجام تحلیل آماری و با توجه به پیشینه تحقیق مشخص شود.
سلام وقت شما بخیر … ممنون از سایت بسیار عالی شما
ببخشید آیا با اس پی اس اس 24 می توان تحلیل مسیر انجام داد؟ من نرم افزار لیزرل یا ایموس ندارم و کار با این ها را بلد نیستم ولی آیا می شود با اس پی اس اس انجام داد؟ ممنون میشم راهنمایی بفرمایید
سلام. لطف دارید.
نه با SPSS نمی شود تحلیل مسیر انجام داد.
دانلود نسخه جدید و کرک شده نرم افزار لیزرل (نسخه10) از وب سایت تخصصی لیزرل:
https://www.lisrel.ir/install-10
سلام.
در مدل رگرسیونی اگر همبستگی پایین باشد(یک دهم و دو دهم) آیا مدل قابل اجراست؟
میزان sig در آن معنا دار است.
سلام. اگر منظورتان ضریب تعیین در رگرسیون است، اعداد یک دهم و دو دهم برای ضریب تعیین بسیار پایین است و مدل خوبی برازش نشده است. هر چند ممکن است مقدار احتمال آماره F مدل معنی دار شده باشد.
با سلام خدمت شما و سایت بسیار مفیدتان
ببخشید سوال من اینه که وقتی همبستگی چند متغیر مستقل رو به صورت جداگانه با متغیر وابسته می سنجم همبستگی همگی مثبت و معنی دار است اما وقتی در نرم افزار PLS به صورت همزمان تاثیر متغیرهای مستقل رو بر وابسته بررسی می کنم بعضی مسیرها منفی میشه.
لطفن در صورت امکان بفرمایید چرا برخی مسیرها منفی می شوند و در توضیح آنها چی باید نوشت چون اگر بنویسم که تاثیر این متغیر بر دیگری منفیه از نظر تئوری درست نیست و همبستگی پیرسون آنها نیز مثبت بوده.
بسیار ممنونم
سلام. در بعضی مواقع رابطه ی دو به دو متغیر مستقل و وابسته برقرار است. ولی وقتی چند متغیر مستقل روی یک متغیر وابسته تاثیر می گذارند به دلیل تاثیری که متغیرهای مستقل روی هم دارند و هم خطی بین متغیرهای مستقل، در نهایت، نتایج متفاوت می شود.
من موع پایان نامم بررسی دومتغیر مستقل و یک متغیروابسته هست و از رگرسیون چندگانه برای بررسی استفاده کردم. اما نتایج نشون داد مقدار sig از0.05 بسیاربالا دراومد و هیچکدوم از متغیرهای مستقل تاثیری در متغیروابسته نداشتند .درصورتی که کاملا بانتایج تحقیقات قبلی مخالف است؟ همچنین مجموع تعداد سوالات تحقیقم ۱۵۵سوال(یک پرسشنامه ۹۰سواله یک پرسشنامه ۳۰سواله و یک تست ۳۵سواله هست)ایا تعداد سوال بالا تاثیری در هیچی بدست نیومدن شده؟ همچنین فقط توزیع داده متغیر وابسته نرمال نیست. خواهش میکنم سریع پاسخ بدین چیکارکنم😔😔😔😔😔😔😔😔
سلام وقت بخیر.سوالی از خدمتتون داشتم : در بررسی نرمال بودن متغیرهامون فقط باید متغیرهای مستقل و وابسته پژوهشمون نرمال باشند تا بتونیم از روش همبستگی پیرسون استفاده کنیم یا لازمه خرده مقیاس ها یا ابعاد هر کدوم از متغیرها هم نرمال باشه؟
سلام وقتتون بخیر. ممنون که وقت می ذارید و جواب می دهید. بنده موضوع پایان نامه م بررسی رابطه بین سبک های مدیریت کلاس اساتید با دلزدگی تحصیلی دانشجویان است و اهداف کلی هم هم بر اساس عنوان و اهداف جزئی شامل بررسی رابطه هرکدام از سبک های مدیریت تعاملی، مداخله گرا و غیر مداخله گرا با دلزدگی تحصیلی هستش. سوال داشتم برای آمار استنباطی از چه آزمونی استفاده کنم؟ کلا چه مواردی لازم است؟ آزمون پیرسون کافی است یا خیر؟ اگر بخواهم رگرسون استفاده کنم باید حتما اهداف رو تغییر بدهم یا باید عنوان هم تغییر بدم به پیشبینی؟ و یه سوال دیگر باتوجه به اینکه تا الان دو متغییر با هم بررسی نشدند روش پیرسون که مختص تایید رابطه است، بهتر است یا رگرسیون استفاده کنم و پیشبنی ، مثلا سبک مدیریت تعامل گرا چقدر دلزدگی تحصیلی رو پیشبینی می کند.
لطفا راهنمایی کنید ممنونم
سلام وقت بخیر. در تحلیل من همبستگی بهعضی از متغیرها بالا تر از متغیرهایی است که وارد معادله تحلیل مسیر شده اند. منظورم از همبستگیف همبستگی پیرسون ومعادله هم با اموس اندازه گیری شده. مثلا همبستگی برونگرایی با رضایت 25 و وظیفه شناسی 16 شده ولی وظیفه شناسی تو معادله معنادار شده دلیل چی میتونه باشه؟
ممنون میشم پاسخ بدید